杭州2017年10月13日电 /美通社/ -- 10月11日,2017阿里云栖大会在杭州云栖小镇举行,这次大会吸引了来自全球近5万名嘉宾参会,堪称史上较强。作为阿里在数据中心与 AI 计算基础设施的重要合作伙伴,浪潮在阿里展台发布了基于 F10A 的 AI 线上推理、GZip 算法与 WebP 图片转码三大云场景 FPGA 加速方案,在扩充 FPGA 生态的同时,也将为从事 AI 开发与应用的公司以及大型数据中心用户,提供更高性能功耗比的专用加速芯片选择。
AI 是壮观云栖大会的热点
“飞天·智能”是本届大会的主题,对于人工智能的发展与未来,马云在首日的演讲中谈到:“当同一件事情几个方向都在谈的时候,意味着一个时代的到来。”他认为:“人工智能,机器应该像人一样会学习,而不是和人一样思考,”同时也提醒到,“对于下一次技术革命,如果没有想象、没有担当、没有学习能力和认知能力,人类是悲哀的。”
异构计算是当今 IT 业界公认的实现高效人工智能计算、加速人工智能创新的新一代计算架构,通过使用特性不同、架构不同的不同计算单元,人工智能计算能够获得较佳的计算性能、计算效率和计算经济性。
在云栖大会的异构计算&高性能计算分论坛上,阿里云异构计算高级专家龙欣就表示:“阿里云正在以异构计算为核心构建业务永续、高性能、高性价比、弹性的人工智能引擎。”而对于异构计算中正扮演越来越重要角色的FPGA,龙欣强调:FPGA 具有能耗比、低延迟、高带宽、常规浮点运算力迅速迭代提升等突出优势。此外,FPGA 作为硬件加速+硬件可编程的技术,可以“在云上运行硬件自定义逻辑”的特点可以满足不同的应用定制化需求,是“专用计算中的多面手”。
浪潮推出领先的 FPGA AI 加速方案
AI 同样是浪潮最重视的未来战略级技术,并致力于为高速发展的人工智能应用需求不断创新设计&提供顶尖的 AI 计算产品方案。2017年浪潮在人工智能计算的数据中心产品创新、深度学习算法框架优化、生态系统建设等方向已全面发力。
此次浪潮发布的三大 FPGA 加速方案全部基于自主研发的 F10A,这是目前业界支持 OpenCL 的较高密度、较高性能的 FPGA 加速设备。F10A 的单芯片峰值运算能力为 1.5TFlops,而功耗仅 35W,每瓦特性能达到 42GFlops。同时,F10A 设计半高半长 PCI-E 插卡,具有灵活的板卡内存配置,较大支持 32G 双通道内存,能够寄存更多的并行任务数据。此外,F10A 支持2个 10Gb 光口,可以实现数据直接从网络到板卡处理,无需经过 CPU,减低了传输延时。
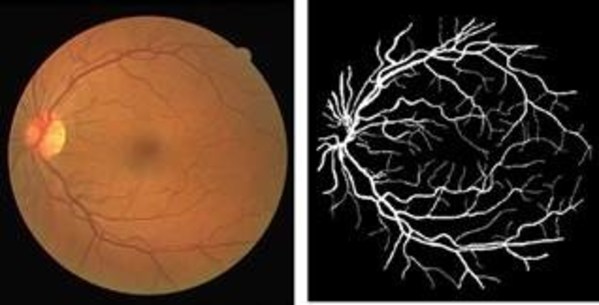
基于 FPGA 具有可编程专用性,高性能及低功耗的特点,浪潮 F10A AI 线上推理加速方案针对 CNN 卷积神经网络的相关算法进行优化和固化,可加速 ResNe t等神经网络,能够应用于图片分类、对象检测和人脸识别等应用场景。
实测数据显示,在进行 ResNet 残差网络的图片识别分类任务时,浪潮 F10A 加速方案图片处理速度可达每秒742张,Top-5 识别准确率达到99.6%,相比同档次 GPU 能效比提升7倍以上。而与通用 CPU 对比,在处理这种高并行、小计算量的任务时,F10A 的优势将更明显。
值得一提的,浪潮 F10A AI 线上推理加速方案部署非常简单,用户只需要将目前深度学习的算法和模型编译成与浪潮深度学习加速解决方案的配置脚本,即可进行线上应用,省去至少3个月到半年的开发周期和相关成本。
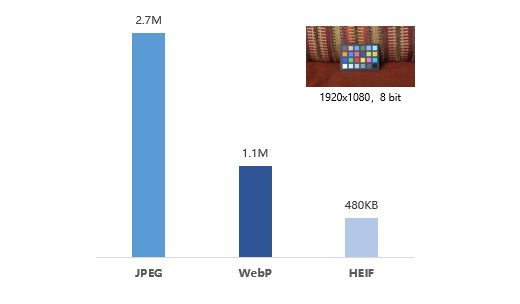
此外,浪潮推出的 WebP 图片转码 F10A 加速方案,针对图片数据的压缩嵌入基于 FPGA 计算环境下的 WebP 编解码优化算法,通过充分利用硬件流水设计和任务级并行,大大提升 WebP 图像压缩编码算法的处理性能,能够实现 JPEG-WebP 图片格式的快速转换,比传统实现方式的整体处理效率平均高9.13倍左右,较高性能可比 CPU 提高14倍。而为了解决传统压缩架构的弊端,浪潮 F10A GZip 算法加速方案充分利用板卡硬件流水设计和任务级并行,大幅提升了压缩任务的吞吐量并有效降低 CPU 的负载,压缩率较高可达94.8%,压缩速度达到 3.2GB/s,10倍于传统方法的压缩效率。
目前,浪潮已占有中国 AI 计算服务器市场60%以上份额,与百度、阿里、腾讯、科大讯飞、奇虎360、搜狗、今日头条、Face++ 等人工智能领先公司保持在系统与应用方面的深入紧密合作,帮助客户在语音、图像、视频、搜索、网络等方面取得数量级的应用性能提升。相信随着三大场景 FPGA 加速方案的推出,将让浪潮在 AI 计算领域保持更大的竞争力与领先优势。