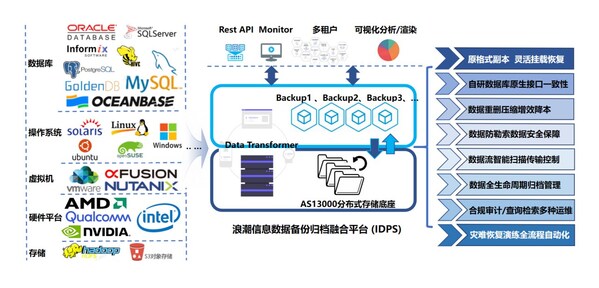
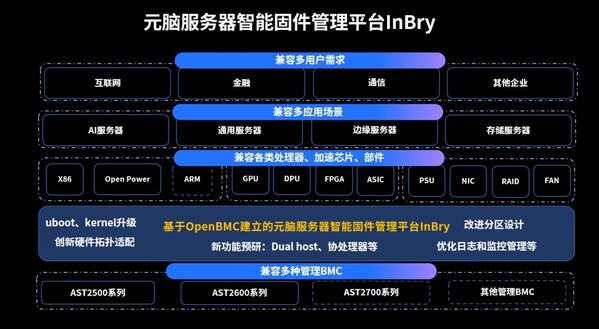
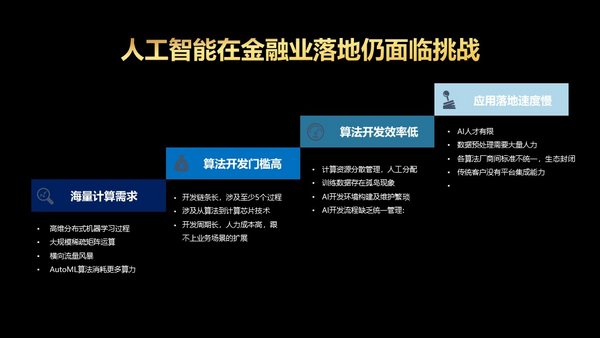
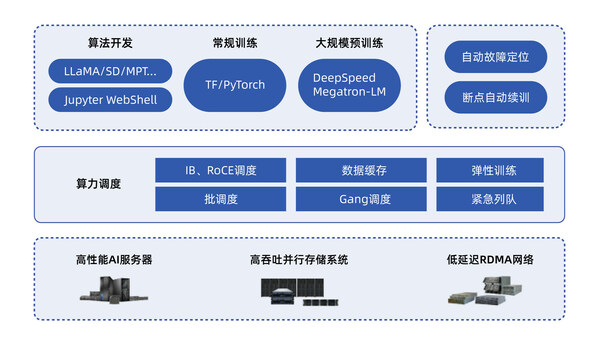
北京2020年12月21日 /美通社/ -- 近日,浪潮重磅升级人工智能开发平台AIStation3.0,打造更加完善和快捷的生态伙伴产品对接能力,实现与元脑生态伙伴的多元化AI开发工具、模型算法与解决方案无缝对接、融合,推动AI应用在实际生产环境中的敏捷开发、快速部署与持续创新。
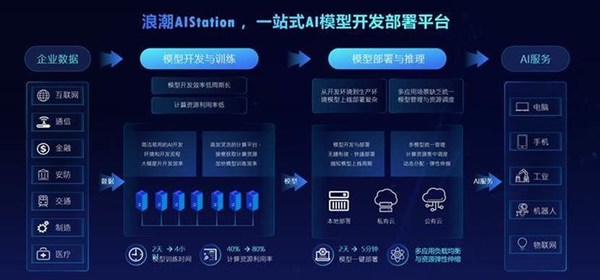
作为智慧计算的领导者,浪潮打造了领先的AI计算解决方案,以AI算力平台、资源平台与算法平台,为AI产业化和产业AI化提供集约高效的智算力支撑。其中,AIStation作为浪潮领先的AI资源平台,能够为AI模型开发训练与推理部署提供从底层资源到上层业务的全平台全流程管理支持。通过对计算资源、数据资源、深度学习软件栈资源进行统一管理,AIStation为环境构建、模型开发、模型训练、模型评估、模型推理、上线部署全链条全面提速,帮助企业提升资源使用率与开发效率90%以上,并将模型的部署时间从两三天降低到几分钟,加快AI开发应用创新。
生态强大 无缝对接100+算法、工具与数据集
最新升级的AIStation采用“能力中台”的高效开发架构设计,基于标准的接入规范和管理适配层,能够更加敏捷地融合元脑生态伙伴的AI产品技术,实现对合作伙伴各类AI开发工具、模型算法的无缝对接和统一管理。
在模型开发方面,AIStation实现数据标注、性能调优、迁移学习、联邦学习等第三方工具的快速集成,加速用户模型开发迭代。在模型服务方面,AIStation可以高效集成合作伙伴的AI应用,例如图像识别、OCR识别、语音识别、智能客服、智能风控等,通过对模型与算力的统一管理,加速AI应用的场景落地。
目前,AIStation 3.0已无缝链接100+AI算法模型、开发工具与数据集,并与超过50+合作伙伴联合开发了涵盖智慧金融、智慧医疗、智慧城市、智慧教育和智能制造等行业解决方案,为行业客户提供全链条的AI场景化服务。
释放AI算力 打造领先的算力调度能力
在AI算力调度方面,AIStation 3.0已全面支持最新NVIDIA® Ampere架构芯片,支持GPU多实例的灵活划分,用户可以通过管理界面动态调整GPU算力组合,从单卡多实例的细粒度划分,到多机多卡的大规模并行计算,帮助用户最大限度释放算力资源。
在加速芯片方面,AIStation3.0基于标准规范实现对GPU、FPGA、ASIC等异构加速芯片的插拔式使用,将各类加速器的性能充分发挥,可大幅提高系统的整体计算性能。
此外,AIStation 3.0将提供更弹性的算力运行策略,实现运行环境与运行资源的隔离,开发者可以在不改变运行环境的情况下按需对资源进行伸缩,如CPU、GPU等异构计算资源,让开发者不必关注底层算力技术,算力随用随取,按需分配,快速响应,进一步提高开发训练效率。
通过领先灵活的算力调度运行策略,AIStation可以为企业级用户提供稳定、高效的算力输出,灵活满足模型开发、调试、训练等不同场景下的算力需求,从单卡多实例的细粒度划分,到多机多卡的大规模并行计算,帮助用户最大限度释放算力资源,有效提高投资回报率。
提速AI技术创新 推进产业AI化
浪潮AIStation致力于提供为AI全生命周期提速赋能的人工智能开发平台,持续集成并输出领先的技术能力与工具,帮助开发者实现AI技术开发与应用的创新突破。
目前,借助浪潮AIStation人工智能管理平台,众多行业客户的人工智能开发部署效率已经得到显著提升,在交通银行、国家电网、爱驰汽车、一加手机等多个行业,AIStation帮助用户获得超过200%的开发效率提升。最新升级的AIStation 3.0通过标准API接口开放底层计算资源的管理调度能力,可让用户既有AI业务与AIStation平台无缝对接,进一步提升AIStation与各企业业务的适配度。
未来,浪潮将不断创新升级AIStation,打造业内领先、功能强大、生态丰富的AI资源平台,结合浪潮领先的AI计算平台与AI算法平台,推动智算力作为生产力赋能千行百业,创造智慧新格局。