杭州2017年10月14日电 /美通社/ --
10月11日, 2017阿里云栖大会在杭州云栖小镇举行,这次大会吸引了来自全球近5万名嘉宾参会,堪称史上较强。作为阿里在数据中心与AI计算基础设施的重要合作伙伴,浪潮在阿里展台发布了基于F10A的AI线上推理、GZip算法与WebP图片转码三大云场景FPGA加速方案,在扩充FPGA生态的同时,也将为从事AI开发与应用的公司以及大型数据中心用户,提供更高性能功耗比的专用加速芯片选择。
以下为发布现场的演讲实录。
面向FAAS服务的FPGA加速卡
我们看到,应用逐步向云环境迁移,2020年,预计65%-85%的应用迁移到云环境中,对公有云、私有云和传统云数据中心来说,公有云具有较高的负载密度和性价比,将成为云服务应用的主流形态。
当前一些以深度学习为代表的新兴计算应用给云数据中心和云服务带来了重大挑战,异构计算成为解决这一挑战的关键要素,成为一种新常态。异构计算云服务也给我们带来一个新的盈利模式,对于云应用租户来说,感受的是时间,时间就是金钱。如果通过异构加速,缩短服务所需的时间,可以节省很多的费用支出。对于面向云应用租户提供SaaS服务的厂商来说,单位时间内生产效率的提升可以给他们带来更多的收益,也提升了他们的提供云服务的积极性。对于公有云厂商来说,一方面,通过异构计算,可以显著降低系统的能耗,节约成本,另一方面,异构计算给云应用租户和SaaS服务商带来更多的好处,使得大家更踊跃的参与,这将形成多赢的局面。对于异构计算加速部件,可以有GPU、FPGA、ASIC或者以TPU为代表的专用加速器等多种选择。其中,GPU使用最广,生态系统最成熟,在深度学习方面取得了良好效果。
与CPU和GPU不同,FPGA是一种典型的非诺依曼架构,是硬件适配软件的模式,它能够根据系统资源和算法特征灵活的调整并行度,达到最优的适配,因此能效比高于CPU和GPU。对于ASIC专用加速器来说,它们在专用算法的加速方面会有比较好的效果,但难以满足云服务对计算部件具有广泛适用性的需求。
以TPU为代表的各种PU们在深度学习加速方面取得了较好的效果,通常拿来与FPGA竞争、比较,这让我们想起了20年前计算机体系结构超标量(Supersclar)和超长指令字(VLIW)之争,超标量架构通过硬件发掘程序的并行性,但在4发射(4-issue)以上遇到了很大的困难,为了发掘程序的并行性并消除数据相关性和流水线冲突,付出了很大的硬件代价,同时使得处理器的工作主频难以提升。而超长指令字将程序并行性发掘任务交给了编译器,同时简化了数据相关性、流水线冲突处理单元设计,以期望实现更高的工作主频和更好的性能。但是理想很美好,现实很残酷,编译器很难从现有的编程模式下发掘更高的并行性。超长指令字并不能发挥,因此现在的主流CPU依然采用超标量架构。FPGA更像一种类似超标量的架构,提升算法并行性的模式,对于TPU来说,其Tensorcore采用的脉动阵列架构处理方式,对数据复用性很敏感,对于像残差神经网络(Resnet)这种小规模矩阵运算(如1*1矩阵)效果存在折扣。另一方面,TPU类似于超长指令字架构,简化了数据控制逻辑单元,需要通过框架优化和编译器优化来发掘并行性,消除数据相关性,应用场景受到限制,短时间内难以满足云服务通用性的要求。因为,我们认为,FPGA 是继GPU之后,第二种具有更高能效比、更好通用性云服务加速部件。
其实FPGA不仅在计算的加速具有良好效果,其也可以应用于数据中心存储和网络的加速,FPGA可为云服务计算、存储、网络带来综合的提升。
FPGA作为一个加速卡,已经有几十年的历史。但是在数据中心应用有所不同,FPGA首先要提供云服务,能够满足大规模部署和运维的需求,满足云服务的特性,包括远程监控管理、在线动静态逻辑的重构,也需要支持各种虚拟机访问以及支持各种驱动兼容性,整个加速卡也需要有更高的RAS特性,这些在服务器里面,可能是比较通用的性质,但是先前的FPGA加速卡,并没有这类应用场景需求,也不具备这些特性,存在很大缺失。我们认为,FPGA更重要的是一种FaaS(FPGAas a Service)服务。
在这里介绍一下浪潮研制的面向 FaaS(FPGA as a Service)服务的FPGA加速卡。它是业界功能密度较高的半高半长加速卡,它与其他卡的显著不同之处在于在半高半宽的尺寸下支持双DIMM模式,而不是内存贴片。采用内存贴片的方式,将会带来较好的散热效果,但内存容量受限,同时,现在内存存在一些良率问题,采用贴片内存就需要筛选,如果筛选不好的话,FPGA卡,可能如果发生内存的故障,会不可修复,可能会带来FPGA里头的通道,或者很大一块(08:卡可能发成内存故障,不可修复,可能会带来FPGA内存访问通道的缺失,或者一大块内存空间失效,影响整个板卡的使用,因为浪潮采用DIMM的方式,并克服了DIMM方式带来的一些问题,如信号完成性和散热要求高要求。浪潮的FPGA卡每个DIMM较大可支持16GB,所以我们半高半长的板卡较大可以支持32GB内存,比其他板卡高出一倍以上,它的峰值浮点性能可以达到1.5TFlops。浪潮作为服务器厂商,其FPGA加速卡不仅仅是一个板卡,而是将很多的服务器技术转移至其中,构建了一个支持FaaS服务的FPGA生态系统。
板卡能够支持动态逻辑的在线可重构、静态逻辑的远程更新,采用带内(CPU-PCIE-FPGA)带外(BMC-SMBUS-CPLD)双环监控管理机制,大大提升了板卡远程监控管理的可靠性,通过它们可以实时的监控FPGA芯片的温度、板卡风扇转速、板卡序列号、板卡内存特性并可以调整FPGA的工作频率。
同时也支持虚拟机的直接访问,板卡本身也加入了很多RAS特性,如高可靠内存访问等。板卡支持并行(FPP)和串行(AS)双加载模式,任何一种模式加载出现故障,都可以快速切换到另一种模式加载,保证了板卡大规模服务的可用性。
基于OpenCL高级语言的FPGA一体化解决方案
传统的FPGA的开发类似于芯片的开发,采用硬件描述(RTL)语言开发,RTL开发带来的问题就会像芯片设计一样周期会比较长。一个典型的应用开发,我们首先要进行架构设计,然后我们要写算法的C模型,C模型做完验证之后,RTL工程师使用RTL语言改写一遍,写后需要仿真综合,如果我们发现时序达不了标,可能要调整时序,甚至要推倒重来重新优化设计,时序达标后,首先要跟C模型进行联合仿真验证,验证完毕还要上板卡进行测试验证,板卡级的测试验证会有很多问题,尤其是人工开发引入的时序、时钟问题,发现难验证难。因此,要开发一个大型应用可能需要一年的时间。当然,现在有一些HLS(HighLevel Synthsis)的工具,它可以把C模型直接翻译成RTL模型,但是它的主要问题是开发不是特别友好,它仅仅把算法实现了,但是算法周边,包括总线接口、访存单元、驱动、上层的调用都存在着空白需要额外开发。因为RTL工程师仅仅把它当成一个辅助的开发工具,整体开发时间并不能节省太多。
互联网存在快速开发和迭代开发的特性,以满足线上应用快速变化的需求,RTL或HLS开发模式动辄以半年或年为单位的开发周期难以满足需求,迫切需要更高层次的开发模型。OpenCL高级语言开发方式为我们打开了一扇窗户,它把底层的硬件如总线、IO接口、访存控制器等和底层软件如驱动、函数调用等全部封装在BSP中,变成标准单元提供上层支持。用户只需要关注算法本身,OpenCL的开发的逻辑通过编译工具直接映射到FPGA中,开发周期大大缩短,也符合互联网应用的需求。
Gzip数据压缩
基于OpenCL语言浪潮开发了一些解决方案,下面我们讲一些案例,以数据压缩Gzip为例,存储面临的压力远远高于计算,数据产生可以分为两类,一类是人类产生的数据,比方说,文本、图片和视频等,它的特点是随机性高、重复率低,另一类是机器产生的数据,包括交易记录、编译报告和日志等,这类的数据其实比我们人类产生的要多的多,它的特点是随机性比较低,重复率非常高。对于压缩来说,怎么样把各类数据都进行很好的压缩,是个很大的挑战。
对于FPGA压缩方案业内通用的是一种简化方案,它把Gzip重要的两个部件LZ77压缩、Huffman并行执行,牺牲了压缩率,不兼容Gzip标准算法。
针对这些问题,浪潮推出了完全兼容Gzip标准的FPGA压缩算法,并且提供两种方案,一种是高性能的(High Performance)的方案,另一种是高压缩率的方案。数据对比表明,采用简化方案虽然性能可以达到2.5GB每秒,但压缩率只有45%,浪潮的高性能方案和高压缩率方案性能可以到1-1.5GB每秒,压缩率可达25%-28%,比简化方案提升了50%以上。 另外,在机器产生的日志文件压缩中效果更加明显,压缩率能到5%,而简化的方案只能到26%-27%左右,浪潮的方案提升了5倍,这是非常显著的一个数据,因为现在很多互联网厂商,他们每天的日志文件,都是TB级的,所以减少5倍存储开销是非常可观的数字。
与CPU软件方案相比,在文本上面压缩上与其接近,在日志文件压缩上与其差距不大,但性能提升了10-20倍。现在较快的SSD数据写入速度大约在1GB每秒左右,浪潮FPGA加速方案可以实现实时压缩和存储。
图片转码FPGA加速
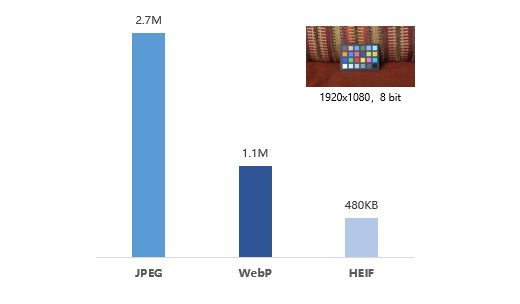
WebP是谷歌提出的一种图片编码格式,它能够在保证图象质量的同时,进一步压缩图片存储空间,比PNG、JPG、GIF格式有25%-60%的存储空间减少。对于数据中心来说,网络带宽其实是很大的一块运营成本。谷歌的数据表明,Webp格式可减少33%的网页传输时间,同时整体加载时间可以减少10%。腾讯的数据表明,采用Webp格式,其新闻客户端、QQ空间等,流量峰值带宽降低9GB,图片延时和数据下载延时降低100ms。因此采用WebP的方式不仅仅能够数据每天节省TB级的数据存储空间,同时也能有效降低网络带宽的开销,从而降低整个数据中心的运营成本。从VGA(640*480)到4K高清各种尺度下的测试表明,浪潮FPGA的WebP编码性能可提升10倍以上。
深度学习
浪潮FPGA在深度学习线上推理应用也做了很多尝试。首先是AlexNet深度学习网络,单机单卡性能可达到848桢每秒的线上识别率。我们也尝试单机双卡、三卡到四卡性能加速,在单机四卡情况下,可达到2971帧每秒的线上识别率。而且,从单机到单卡到四卡,它们的性能提升线性度非常好。
另外,我们也构建了两种残差深度学习网络加速模型,一种是采用CIFAR-10的57层神经网络,另一种采用ImageNet数据集的50层神经网络。浪潮作为一家服务器厂商,可以提供包含FPGA板卡、BSP和驱动、IP算法,同时可以集成在我们的服务器中给客户提供一体化的解决方案。