北京2022年12月8日 /美通社/ -- 自动驾驶是集感知、决策、交互于一体的技术。环境感知能力作为自动驾驶的第一个环节,是车辆与环境交互的纽带。通过"摄像头、毫米波雷达、超声波雷达、激光雷达"等各类传感器设备,感知环境的手段日趋多元化。同时,在平台层面感知决策处理能力的提升,平台算力和感知算法的效率提升和创新,也成为了车企发展智能驾驶能力的关键。
NuScenes挑战赛,作为检验感知算法在自动驾驶领域相关任务性能的试金石,自数据集公开以来,吸引了来自全球各地的研究团队的结果提交。
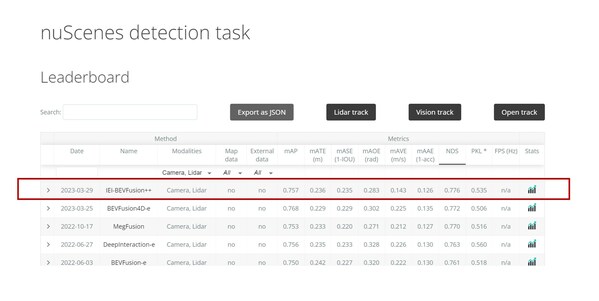
在最新一期所公布的竞赛测评榜单中,全球领先级AI算力基础设施提供商----浪潮信息凭借Inspur-DABNeT4D登顶自动驾驶数据集NuScenes 纯视觉3D目标检测任务榜单,并将关键性指标NuScenes Detection Score(NDS)提高至62.4% 。
除传统的自动驾驶创业公司和造车企业之外,人工智能平台厂商、算力厂商也开始逐步关注和投入自动驾驶的技术研发。那么,未来自动驾驶感知技术究迈向如何的路径发展,逐步实现大规模的量产落地?
本文试图从浪潮信息在NuScenes榜单上的感知模型解读出发,来一窥自动驾驶的感知技术发展。
从自动驾驶的分级来看,当前的自动驾驶技术,隐隐可以看出2个流派,一个是以直接实现L4级自动驾驶为目标的激进派,一个是从L2级辅助驾驶开始,逐步提升自动驾驶等级的渐进派。但无论是L2级的辅助驾驶还是L4级的自动驾驶,从整体架构上看,都可以大致分为感知、决策和控制3部分。感知是自动驾驶汽车的眼睛,和人类的眼睛为大脑提供了70%以上的信息类似,感知系统也为自动驾驶车辆提供了车辆外部环境信息输入。自动驾驶的感知依赖于各种车载传感器的信息输入,包括摄像头、超声波雷达、毫米波雷达和激光雷达等。其中最核心的就是摄像头和激光雷达。
:自动驾驶架构组成 。图 2(下):3D目标检测示意图, 3D目标被定义为一个长方体,(x,y,z)是长方体的中心坐标,(l,w,h)是长宽高信息,θ是航向角,比如长方体在地平面的偏航角,class是3D目标的类别。vx、vy描述3D目标在地面上沿x轴和y轴方向的速度。")
图 1(上):自动驾驶架构组成 。图 2(下):3D目标检测示意图, 3D目标被定义为一个长方体,(x,y,z)是长方体的中心坐标,(l,w,h)是长宽高信息,θ是航向角,比如长方体在地平面的偏航角,class是3D目标的类别。vx、vy描述3D目标在地面上沿x轴和y轴方向的速度。
自动驾驶面对的是一个3维的环境空间,甚至于我们可以说,因为自动驾驶车辆要在环境空间中移动,且环境空间中其他的行人、车辆等也会移动,则可以看作自动驾驶面对的是一个3维空间+1维时间的4维时空体系。自动驾驶车辆需要在三维空间中判断周围的人、车、物的距离远近,在此基础上还要判断他们是静态或者动态的,以及移动的方向和速度等信息,我们一般称之为3D目标检测任务。3D目标检测任务可以看作是自动驾驶中最核心的感知任务。当然,除此之外,其他的感知任务还包括识别红绿灯、交通标识、车道线、斑马线等道路信息。
长期以来,激光雷达一直被认为是自动驾驶车辆不可或缺的零部件之一,因为激光雷达能提供对车辆周围环境最精确的三维感知。激光雷达采集的点云信息天然就存储了三维空间信息,因此基于激光点云信息的3D目标检测来说,算法设计就简单了许多,也诞生了一系列的经典模型,比如PointPillar、SECOND、SASSD等等。但是激光雷达的成本问题也成为了自动驾驶落地最大的瓶颈。早期的激光雷达价格,比如激光雷达鼻祖Velodyne推出的高精度激光雷达的价格达到了8万美元。雷达比车贵的现实问题成为了激光雷达上车和量产的最大阻碍。虽然今年随着技术的进步,激光雷达的价格下降明显,但是能满足L4级自动驾驶需求的激光雷达的价格依然偏高。
摄像头是自动驾驶车辆的另外一个非常重要的传感器,因为激光雷达采集的点云信息没有色彩和纹理,因此无法识别对于人类来说可以轻松辨别的红绿灯、交通标识、车道线、斑马线等道路信息。因此还是需要摄像头作为补充。而这又会带来额外的多个模态的信息融合难题。简单来说,激光雷达主要擅长三维空间中的车辆、行人等的三维时空信息感知,而摄像头主要擅长除此之外的红绿灯、车道线等视觉纹理特征比较丰富的信息感知。另外,在量产成本和价格上,摄像头也有无可比拟的优势。比如Tesla搭载的单颗单目摄像头的成本仅为25美元,整车8个摄像头的价格也才200美元。相比于整车价格来说,几乎可以忽略不计。如果仅使用摄像头,在强大AI算法的加持下,就能实现精确的3D目标检测任务,那意味着不使用激光雷达的自动驾驶也不无可能。
在计算机视觉领域,近年诞生了大量的分类、检测、分割模型,比如ResNet、YOLO、Mask RCNN等,这些AI模型已经广泛的应用于安防、交通、以及自动驾驶领域。但有一个核心的问题是,这些模型都是针对2D图像设计的,无法直接适用于3D目标检测任务。基于图像进行3D目标检测的核心问题就是如何精确的估计图像中物体的深度。因为摄像头拍摄的照片和视频是把3D空间投射到了2D平面中,丢失了深度信息,如何对这些深度信息进行还原就是一个机器学习领域所谓的"病态问题"。即,问题的解可能不是唯一的。因此长期以来,基于图像的3D目标检测算法性能一直远低于基于激光雷达的3D目标检测性能。
自从Tesla使用纯摄像头方案的辅助驾驶系统取得一定的成功之后,基于纯视觉的自动驾驶感知方案受到了业界越来越多的关注。同时随着数据、算法、算力等多个方面的进步,纯视觉的自动驾驶感知方案在3D目标检测任务上的性能在最近一年和激光雷达的差距有了明显的改观。
在数据方面,出现了搭载传感器更多,采集时间更长的自动驾驶道路数据集。比如2019年由Motional(由现代汽车集团和Aptiv资成立的一家无人驾驶公司)的团队开发和开源的NuScenes数据集采集于波士顿和新加坡两个城市的实际道路。收集了大约15小时的驾驶数据,精心选择驾驶路线以捕捉具有挑战性的场景数据。数据场景覆盖了城市、住宅区、郊区、工业区各个场景,也涵盖了白天、黑夜、晴天、雨天、多云等不同时段不同天气状况。采集车上配备了完善的传感器,包括了6个相机、1个激光雷达、5个毫米波雷达、以及GPS和IMU,具备360°的视野感知能力。NuScenes数据集是第一个提供自动汽车全套传感器数据的大型数据集。
除了NuScenes之外,业界还有Waymo、ONCE等开源数据集。但目前NuScenes是被使用最多的数据集。自公开以来,NuScenes数据集已经被论文引用超2000次。NuScenes挑战赛也成为了检验感知算法在自动驾驶相关任务性能的试金石。吸引了来自全球各地的研究团队的220余次结果提交,不仅有百度、华为、商汤、旷视等知名企业,还涵盖了卡内基梅隆大学、加利福尼亚大学伯克利分校、MIT、清华大学、香港科技大学、上海交通大学、中国科学技术大学等国内外重点高校。近期,鉴智机器人、纵目科技、亿咖通等车企研发团队也出现在了NuScenes的榜单上。
NuScenes数据集提供了包括 3D 目标检测、3D 目标跟踪、预测轨迹 、激光雷达分割、全景分割和跟踪在内的多个评测任务。其中3D目标检测任务的目标是检测NuScenes数据集上的10种不同类别的检测对象,包括标出3D目标框,并且估计相应类别的属性信息和当前的速度信息等。这10种检测对象具体包括汽车、卡车、公交车、行人、摩托车、自行车、锥桶、路障等,检测的信息包括物体的三维位置、大小、方向、速度等。NuScenes 提出了一个综合指标NDS,即NuScenes 检测分数(NuScenes Detection Score, NDS),这个指标由平均精度(mAP)、平均平移误差(ATE)、平均尺度误差(ASE)、平均方向误差(AOE)、平均速度误差(AVE)和平均属性误差(AAE)综合计算得到。

图 3:NuScenes数据集中车身6个摄像头采集画面示意图。
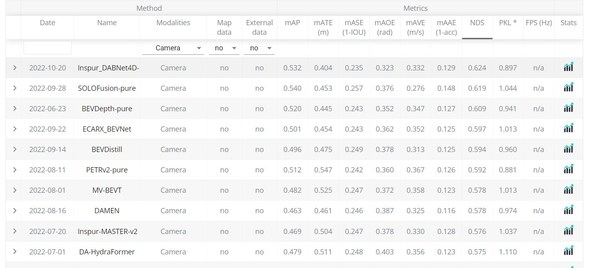
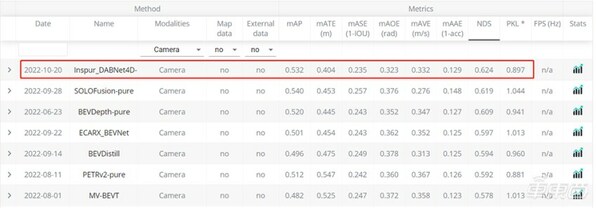
NuScenes提供了一个常年更新的榜单,在纯视觉 3D目标检测任务榜单[1]上,目前一共有50次提交,其中大多数的提交发生在2022年。目前排名第一的是浪潮信息的AI团队在22年10月提交的DABNet4D算法,实现了综合检测精度NDS 0.624的检测效果。而在2022年初排名第一的BEV3D算法的NDS精度是0.474。也就是说在不到一年的时间内,NuScenes 纯视觉3D目标检测的NDS指标提升了15个点。相比之下,基于激光雷达的3D目标检测精度,仅从年初的0.685提升到0.728,提升约4个点。而基于纯视觉算法和激光雷达算法的精度差距也从年初的45%缩小到17%。这主要得益于纯视觉3D检测算法优化带来的性能提升。
:NuScenes评测榜单截图。
图 5(下):把不同视角的图像转换到统一的鸟瞰图(BEV)视角空间。")
图 4(上):NuScenes评测榜单截图。 图 5(下):把不同视角的图像转换到统一的鸟瞰图(BEV)视角空间。
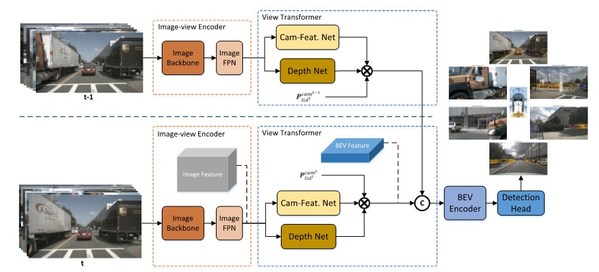
浪潮此次所提交的算法DABNet4D是Depth-awared BEVNet 4D的缩写,即深度感知的四维鸟瞰图(bird's eye view, BEV)神经网络。其核心思想就是构建了鸟瞰图(BEV)神经网络,并使用了时空融合的4D感知和深度预测优化。由于单个摄像头的视角有限,仅使用单个摄像头很难实现对车身周围360度的感知。前期自动驾驶算法模型一般是基于车身不同位置的摄像头分别进行环境感知,然后进行融合。但是这一方案存在一些潜在的问题,比如对于像大卡车这类比较大的车辆挨着自动驾驶车辆时,会在自动驾驶车辆的多个摄像头中出现卡车的不同部位,会导致算法出现错误检测和漏检的情况。最近融合模型架构,通过先对不同摄像头或其他传感器的信息进行融合,然后在一个统一的融合的空间进行3D目标感知和检测,能够有效的解决这些问题,是目前感知技术发展的一大趋势。
所谓鸟瞰图,就是从天空俯视自动驾驶车辆及其周围环境,也就是所谓的上帝视角。自动驾驶车辆的摄像头都是水平视角,如果把不同水平视角的图像融合成一个统一的以自动驾驶车辆为中心的俯视视角的特征图,那么就可以提供最清晰和完整的自动驾驶车辆周围环境空间的视觉表征,从而也就方便从这统一的视觉表征中进行3D目标检测以及其他的检测、分类、分割等视觉感知任务。但是,如何基于AI算法构建这统一鸟瞰图视觉表征是一个很大的挑战。
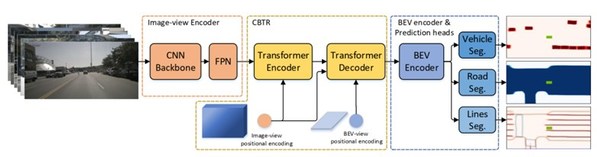
:多相机融合算法架构图。先使用特征提取神经网络对不同视角的图像进行特征提取,并融合到统一的BEV空间,并基于统一BEV空间进行障碍物检测、车道线检测和道路检测等检测任务。
图 7(右):浪潮团队研发的基于Transformer架构的多视角特征融合模型CBTR的架构图。")
图 6(左):多相机融合算法架构图。先使用特征提取神经网络对不同视角的图像进行特征提取,并融合到统一的BEV空间,并基于统一BEV空间进行障碍物检测、车道线检测和道路检测等检测任务。 图 7(右):浪潮团队研发的基于Transformer架构的多视角特征融合模型CBTR的架构图。
在2022年初,浪潮团队构建了一个基于Transformer架构的多视角特征融合模型CBTR。CBTR以经过卷积神经网络提取的图像特征作为输入,并经过标准Transformer架构的特征融合和特征变换,实现了高效稳定的BEV特征输出。以CBTR构建的BEV特征为基础,团队在NuScenes数据集上实现了在精度和速度上都最优的车道线检测算法。相关成果发表在CVPR 2022 WAD上。在DABNet4D中,团队进一步优化了BEV特征的提取网络,以实现更好的特征提取效果。
考虑到车辆所处的环境是一个动态变化的三维空间,引入历史空间数据对于目标的速度和方向的预测将会有比较大的帮助。为了进一步引入车辆所处的动态环境中的历史信息,浪潮团队基于NuScenes中的多帧数据,分别进行BEV特征提取,并使用专门的特征融合模块对时序的特征进行融合,构建了MASTER(Multi-camerA Spatial and Temporal feature ExtractoR,多相机时空特征提取器)算法。2022年7月,团队在NuScenes榜单提交了MASTERv2版本的3D目标检测结果,实现了NDS 0.576的检测精度。位列当前同类型算法第一。
在此基础上,如何进一步提高纯视觉3D目标检测的精度,其核心还是进一步优化模型的深度估计性能。在MASTER算法的基础上,团队进一步引入了深度估计网络,来强化模型的深度感知性能。最终的完整网络架构如下图所示。

图 8:浪潮团队研发的DABNet4D模型架构图。
除此之外,多种数据增强算法的应用,也对DABNet4D的性能提升有比较大的帮助,这主要是因为虽然NuScenes数据集在目前开源的自动驾驶测评数据集中,已经算是比较大的规模,但是其相对于真实的自动驾驶场景来说,数据集的规模还是比较有限,比如有的目标检测类别,在整个数据集中,只出现了很少的次数。这种不同类别目标在数据集中的不均衡性,对于模型整体检测效果的提升,有较大的不利影响。因此DABNet4D使用了图像数据增强、BEV特征增强和样本贴图增强等多尺度的数据增强技术,来提升模型的检测效果。
在此基础上,使用性能更优的特征提取网络对于整体的性能提升也有一定的帮助。团队测试了EfficientNet系列、Swin Transformer系列、ConvNeXt系列等多个典型的视觉特征提取网络,并最终选用了ConvNeXt网络架构以期获得最佳的特征提取性能。
在集合了上述算法和工程化方法上的创新之后,DABNet4D最终实现了NuScenes评测榜单上当前业界最佳的纯视觉3D目标检测精度。
需要提到的是,完善的算力基础设施也在这一工作过程中起到了举足轻重的作用。和训练2D目标检测模型比如YOLO系列相比,DABNet4D的训练需要更多的算力以及更好的算力平台支撑。
本次构建的DABNet4D-tiny和DABNet4D-base两个模型,其参数量分别是59.1M和166.6M。虽然参数量不是特别大,但是由于使用的输入数据分辨率达到了1600x900,远大于ImageNet、COCO等数据集训练2D目标检测网络的图片尺寸,这意味着模型训练过程中的特征图输出也会大很多,从而需要更多的显存空间来存储。与此同时,多相机视角的引入以及时序数据的引入,意味着模型训练需要更大的批尺寸。举例来说,NuScenes数据集有6个相机,如果仅使用连续3帧的时序数据,也意味着模型的输入批尺寸是18。这进一步增大了对训练设备的显存需求。实际上,浪潮团队训练模型使用的是搭载了NVIDIA Ampere 架构40GB和80GB显存的多台5488A5 GPU服务器平台。其中GPU之间使用了NV-Switch全互联架构,来满足模型训练的高显存需求,以及模型并行训练的高通信带宽需求。除此之外,服务器上部署的AISTATION资源管理系统,对于整个任务中的资源管理和分布式训练优化,对于整个模型训练的效率提升,也起到了很大的帮助。
另外,数据的丰富程度对于纯视觉3D目标检测模型的感知性能提升作用明显。这也是为什么在DABNet4D的优化过程中,团队使用了较多的数据增强算法。因为相对于真实的自动驾驶场景和数据集来说,NuScenes数据集的规模还是太小了。比如公开资料表明,Tesla 训练其FSD自动驾驶系统使用了 100万的 8-camera 36fps 10-second videos作为训练数据,其规模远大于NuScenes数据集。DABNet4D使用了大约2000 GPU hours。做同比换算的话,Tesla的FSD的训练需求大约是316 台5488A5服务器训练约1周的时间。其计算需求之大,可见一斑。
在自动驾驶落地的产业化进程中,感知技术作为自动驾驶的核心技术模块,既是起点也是基石。而未来,面向自动驾驶感知算法的研发,也将会投入更为强大的人工智能计算平台予以支撑。作为全球领先的算力提供商,浪潮信息始终践行多角度切入,发挥融合算力、算法等全栈解决方案能力优势,推动自动驾驶领域的技术创新型发展。从NuScenes榜单技术的快速迭代来看,我们有理由相信,随着算力、算法的持续型突破,自动驾驶产业化落地进程也将多一层"腾飞动力之源"。