上海2023年5月9日 /美通社/ -- 越来越多的新车开始配备激光雷达,以提高车辆的自主安全性和实现更高级别的辅助驾驶以及自动驾驶能力。然而,纯人工3D标注和验收的效率低、耗时长、成本高昂。而通过先进的AI技术,利用车载激光雷达和多摄像头,可以自动地对车辆、行人、骑行人等动态道路使用者进行3D物体检测,进而高效率地辅助甚至部分替代纯人工标注。
日前,在由黑芝麻智能主办的"2023智能汽车高峰论坛"上,黑芝麻智能机器学习专家张蕾发表了主题为"基于激光雷视融合的3D自动标注技术助力自动驾驶更上一层楼"的演讲,分享了黑芝麻智能在3D数据自动标注方面的研发进展。
自研系统性能方案比肩世界领先算法
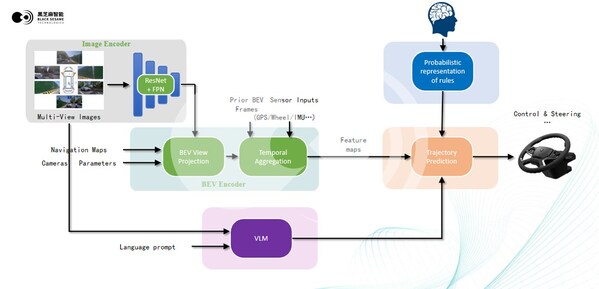
在自动驾驶中需要用道路上目标物3D的位置进行规划和决策,但传统的摄像头解决方案对于深度和3D位置的估计不够准确。在采用了BEV技术以后,需要大量的真实3D标注的数据来辅助训练BEV上的3D模型,这样可以融合多个摄像头的信息,直接去获得3D世界的物体。
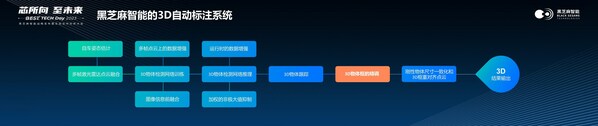
为此,黑芝麻智能自主设计和开发了一套基于激光雷达和多摄像头进行3D自动标注的方案。该方案履行两阶段的方法,第一阶段是先通过多帧点云的方式和图像融合,得到初始的3D标注;第二阶段是以物体为中心的3D精调,进一步提高3D检测精准度。
对于3D物体框的精调,黑芝麻智能采用了两种不同方案。静态物体在多帧点云对齐以后,可以得到一个密度非常高的单个物体点云。在单帧点云里即使看不到一个物体的全貌,但经过以物体为中心的点云融合以后,基本上可以看到完整的物体形状,这样可以更好地估计其尺寸。另一方面,对于动态物体,它的轨迹会形成一个有用的信息,根据动态累计的点云也可以更好地估计其大小和空间上的位置。

张蕾介绍,黑芝麻智能的这一方案,融合了多种模态,目前包括360度激光雷达和六个摄像头的信息,还有前融合和后融合的方式。在两阶段的模型里面,采用的是以物体为中心的点云对齐精调的方式,生成高度紧凑的3D目标检测框。而多帧激光雷达点云的时序融合,能有效弥补单帧点云的稀疏和遮挡问题。同时,整个模型不同阶段可以进行多种融合,下一阶段还可以在整个模型的不同层次阶段进行融合。另外,在采用了跟图像检测做后融合的方法以后,黑芝麻智能还将检测物体的类别从三类扩展到十三类,并且还可以通过聚合的方式实现复杂不规则物体的检测。与此同时,黑芝麻智能的方案,采用了模块化设计,可根据不同需求增加、去除可选的处理环节,达到最优化效益。
根据在Waymo公开数据上测试的结果,黑芝麻智能3D 物体自动标注系统的性能可以比肩世界领先算法的性能。
自建数据采集系统与完整的云服务平台

基于华山二号A1000芯片,黑芝麻智能还可同时提供传感器采集设备,客户可基于这套设备同步采集360度旋转激光雷达和6个1080p摄像头数据,同时采集IMU、GPS、轮速编码器等多种数据。
黑芝麻智能还可以对这一3D自动标注系统做进一步扩展,包括通过差异化的多模型集成来进一步提高算法准确度,通过运行时的数据增强来进一步提高算法准确度,通过半监督学习和自监督学习来训练更好的模型,通过在神经网络深层结构上的多传感器融合来进一步提高模型能力,通过融合聚类方法来检测未知的路面障碍物等等。
张蕾在演讲结尾时表示,在开发基于激光雷达和多摄像头的自动驾驶领域的 3D 物体自动标注系统的同时,黑芝麻智能可为客户提供数据采集、数据预处理、3D 自动标注、人工标注及检验的云服务平台。