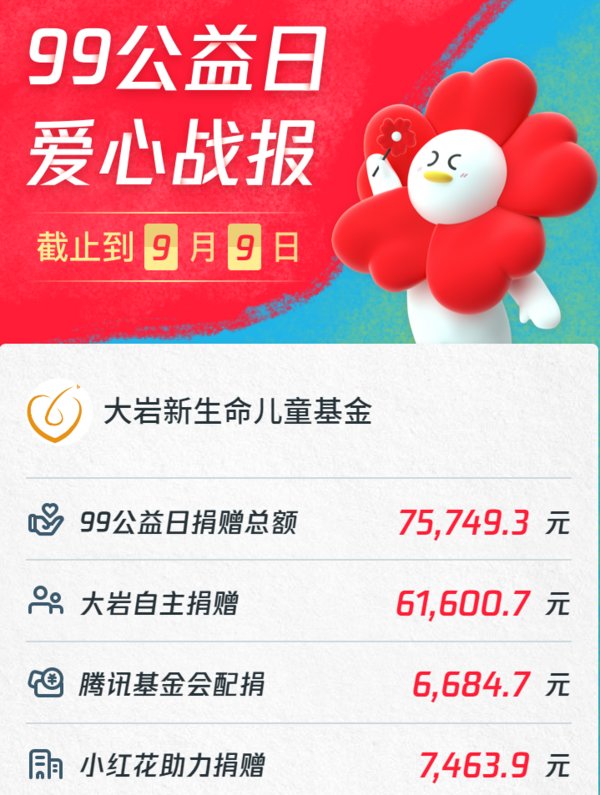
深圳2020年7月16日 /美通社/ -- 近期,大岩资本成立七周年庆在深圳成功举办。周年庆上量化投资基金经理黄铂博士结合生活实践中的案例为大家深入浅出阐释了最优化算法的前世今生。
从实际生活中最基础的应用切入,黄铂博士将抽象的算法概念生动化,解释了什么叫最优化问题、凸优化及算法分类、机器学习与人工智能应用。
黄博士的分享内容较长,我们将分上、中、下三篇连载推出,本文为中篇。
凸优化问题中的最优值

凸优化的关键字在“凸”,我们要定义什么样的东西是凸的呢?看上图,蓝色区域代表优化问题里变量可以取值的空间,当取值空间是凸的时候,这是凸优化的一个必要条件。那么什么样的集合是凸的集合?我们在集合里任意选两点X、Y,我们将这两点连成线,从X到Y的这条线上所有的点都必须在集合里,只有这样的集合才叫做凸的集合。相反,如果有任意一个点在集合之外,那就不是凸的集合。而对于一个凸优化的问题而言,它所有的变量取值必须来自于凸的集合。
所以说,对于所有的离散优化而言,它都不是凸优化的,因为它的取值其实不是一个空间,而是一个洞一个洞的,它是很多洞的集合。所以,通常求解这类问题时很困难,很多时候我们求解的都是一个局部最优值。在实际生活中,我们求解的都是局部优化的问题,而这类问题在所有问题中所占比例是非常非常低的。
如果把整个集合看作一个优化问题的集合,那么相对来讲,比较小的一部分是属于连续优化的问题,其他更大的区域属于离散优化的问题,而在连续优化的空间里只有很小的一部分属于凸优化的问题。所以说,在最优化的领域里,我们真正解决的只是实际问题中的冰山一角。
凸优化问题的经典算法
对于凸优化的问题,黄铂博士给大家介绍几个最经典的算法。
第一个算法,最速下降法。首先,我们看下图,这是一个等高线,我们可以把它理解为我们的高楼,每一个圈代表一层,最中心是最高的位置,我们最终目标是用最快的方式上到中心位置。那么,最速下降法是怎么做的呢?比如从一楼上二楼可以有多种方法,很明显我们从垂直方向往上跳,在局部来看是最快的,然后以这样的方法上到最高层。

最速下降法有哪些特点呢?每一步都做到了最优化,但很遗憾的是,对于整个算法而言,它并不是非常好的算法。因为它的收敛速度是线性收敛,线性收敛对于最优化算法而言是一种比较慢的算法,但也是凸优化里最自然的一个算法,最早被应用。
第二个算法,共轭梯度法。与最速下降法相比较(看下图),绿色的线是最速下降法的迭代,从最外层到中心点可能需要五步迭代,但是共轭梯度法可能只需两步迭代(红色线)。
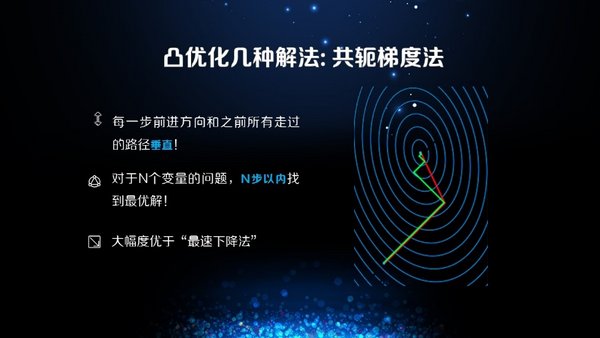
共轭梯度法最大特点是汲取前面的经验再做下一步的动作,比如从四楼上五楼,我们会考虑方向是否最佳,汲取之前跳过的四步经验,再探索新的方向往上跳。从数学的角度来讲,每一步前进的方向和之前所有走过的路径都是垂直的,因为这样的性质,共轭梯度法的收敛速度远远高于最速下降法。
第三个算法,牛顿法。前面两种算法,从数学的角度讲,他们只用到了一阶导数的信息,对于牛顿法而言,它不仅仅用到了局部一阶导的信息,还用到了二阶导的信息。相比前面两种算法,牛顿法的每一步,它在决定下一步怎么走时,不仅考虑当前的下降速度是否足够快,还会考虑走完这一步后,下一步坡度是否更陡,下一步是否更难走。可见,牛顿法所看到的区间会更远,收敛速度更快,属于二阶收敛速度。如果最速下降法需要100步的话,牛顿法就只需要10步,但也正因为牛顿法使用了二阶导的信息,所以它需要更多的运算量。
第四个算法,拟牛顿法。1970年,Broyden、Fletcher、Goldfarb、Shanno四人几乎同一时间发表了论文,对于传统的牛顿法进行了非常好的改进,这个算法叫拟牛顿法,它的收敛速度与牛顿法相似,但是它不再需要计算二阶导数,所以每一步的迭代速度大大增加。它是通过当前一阶导数的信息去近似二阶导数的信息,因此整个运算速度大幅度增加。由于这个算法是四个人几乎同一时间发现的,所以也叫BFGS算法。下图中的照片是他们四个人聚在普林斯顿时拍的,很幸运的是,Goldfarb是我博士时期的导师。
实际生活中,被应用最广的两种算法,一个是BFGS,另一个就是共轭梯度法。这两种算法经常会出现在很多的程序包里或者开源代码里,如果使用在大规模的优化问题或者成千上万个变量的问题中,也会有非常好的效果。(待续下篇)