北京2023年11月8日 /美通社/ -- 2023年,生成式人工智能的爆发带来了历史性产业机遇,正在逐步改造重塑社会、经济、文化等各个领域。GPT-4、Llama2、文心、源等大模型在写文章、对话、企划、绘画、写代码等很多领域已经表现出了让人惊艳的创作能力。未来,AIGC与数字经济、实体经济的深度融合,还将创造出更多颠覆性的社会价值、经济价值。
生成式AI蓬勃发展的背后,算力,尤其是AI算力已经成为驱动大模型进化的核心引擎。计算力就是生产力,智算力就是创新力,已经成为产业共识。大模型时代的算力供给,与云计算时代的算力供给,存在很大的差异性。大模型训练是以并行计算技术将多台服务器形成一个算力集群,在一个较长的时间,完成单一且海量的计算任务。这与云计算,把一台机器拆分成很多容器的需求,存在很大的技术差异。
目前大模型研发已经进入万卡时代,从事大模型研发的公司和团队,普遍面临“买不起、建不了、算不好”的困局。为解决这一困局,需要以算力基建化改善算力供给,促进算力普惠,以算力工程化指导完善算力系统最佳实践,提升算力效率,以模型训练工具化手段,降低模型训练门槛,推动全栈智算系统创新,通过“三化”融合互补,促进产业链条各环节协同配合,加速释放大模型生产力,打造人工智能产业良好发展环境。
算力供给基建化,缓解“买不起”困境
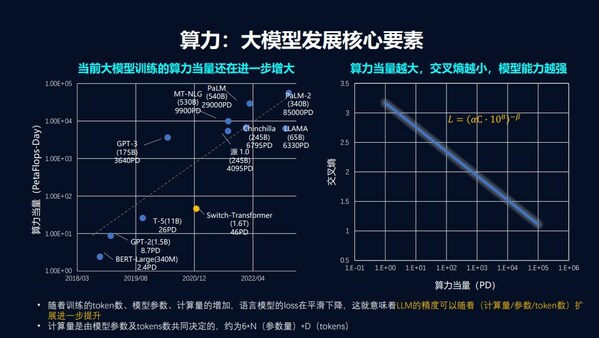
大模型,特别是千亿参数级别具备涌现能力和泛化能力的大模型是通用人工智能的核心。但大模型对海量算力资源的消耗,急剧抬高了准入门槛。以ChatGPT的总算力消耗3640PFdays计算,这对于自建、自研大模型,往往需要少则几亿,多则数十亿的IT基础设施投资,这就导致大模型不仅是一个技术密集型产业,同时也是资金密集型产业,资本的力量在大模型产业发展中扮演越来越重要的角色,高昂的资金门槛使得具备技术能力的初创公司和团队面临“买不起”的难题,难以开展创新。
为解决这一困境,除通过政策引导、政策补贴等方式降低企业融资成本外,还应大力发展普适普惠的智算中心,通过算力基建化使得智算力成为城市的公共基础资源,供用户按需使用,发挥公共基础设施的普惠价值。用户可以选择自建算力集群,或者是采用智算中心提供的算力服务来完成大模型的开发。
通过大力发展智算中心新基建,中国和美国大模型产业的发展已经呈现出完全不同的发展路径。在美国,算力的私有化决定了大模型产业技术只能掌握在少数企业手中,而中国大力推动的算力供给基建化,为大模型创新发展提供了一片沃土,将使得整个产业呈现“百模争秀”的全新格局。
算力效率工程化,化解大模型算力系统“建不了”难题
即使解决了算力供应的问题,通用大模型开发仍然是一项极其复杂的系统工程,如同F1赛车的调校一样。F1赛车的性能非常高,但如何调校好这部赛车,让它在比赛中不仅能跑出最快圈速,而且能确保完赛,对整个车队的能力要求是非常高的。
大模型训练需要依靠规模庞大的AI算力系统,在较长时间内完成海量的计算任务,算力效率十分重要。算力效率越高,大模型的训练耗时越少,就能赢得更多时间窗口,也能降低更多成本。目前,大模型的训练集群效率普遍较低,像GPT3的集群训练效率只有23%,相当于有超过四分之三的算力资源被浪费了。
大模型不应是简单粗暴的“暴力计算”,算力系统构建也不是算力的简单堆积,而是一项复杂的系统工程,需要从多个方面进行系统化的设计架构。一是要解决如何实现算力的高效率,它涉及到系统的底层驱动、系统层优化,与大模型相适配的优化;二是要解决算力系统如何保持线性可扩展,在单机上获得较高算力效率之后,还需要能让几百个服务器节点、几千块卡的大规模集群环境的算力系统运行效率,保持相对线性的性能扩展比,这是在整个算力集群系统设计和并行策略设计时,需要考虑的重要因素。三是算力系统长效稳定训练问题,大模型的训练周期长达数周甚至数月,普遍存在硬件故障导致训练中断、梯度爆炸等小规模训练不会遇到的问题,工程实践方面的缺乏导致企业难以在模型质量上实现快速提升。
因此,化解大模型“建不了”难题,根源在于提升算力效率。但目前业界开源项目主要集中在框架、数据、神经网络乃至模型等软件及算法层面,硬件优化的方法由于集群配置的差异,难以复用而普遍处于封闭状态。这就需要具备大模型实践的公司将集群优化经验予以工程化,以硬件开源项目、技术服务等多种方式,帮助更多公司解决算力效率低下的难题。
模型训练工具化,解决“算不好”难题
系统建成后,大模型在训练过程中,由于开发链条冗长,还面临“算不好”的挑战。从PB级数据的爬取、清洗、过滤,到大规模预训练的算法设计、性能优化和失效管理;从指令微调数据集的设计到人类反馈强化学习训练的优化……大模型训练不仅依赖高质量数据,同时也要解决算法收敛、断点续训、参数优化、模型微调等问题,数据质量、代码调优、执行效率等关乎训练质量的因素至关重要。这些问题解决不好,很难产生一个可商用的、高质量的大模型产品。
解决“算不好”难题,根本上要保障大模型训练的长时、高效、稳定训练的问题。例如大模型训练过程的失效故障,大模型训练会因此中断,不得不从最新的检查点重新载入以继续训练,这个问题在当前是不可避免的。提高算力系统的可持续性,不仅需要更多机制上的设计,更依赖于大量自动化、智能化的模型工具支撑。模型训练工具化保障手段,能够有效降低断点续训过程中所耗费的资源,这意味着大大降低训练成本并提升训练任务的成功率,会让更多公司和团队参与到大模型创新之中。

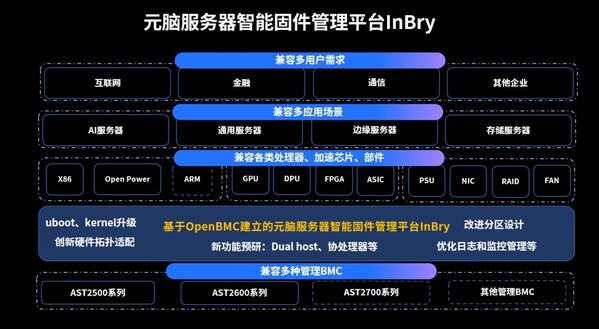
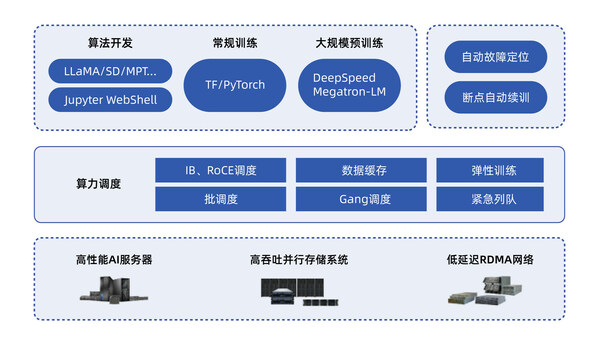
早在大模型热潮到来之前,浪潮信息在2021年已经开始研发参数量达到2457亿的源1.0,通过亲身实践洞察大模型发展和演进的需求和技术挑战。目前,浪潮信息已经建立了面向大模型应用场景的整体解决方案,尤其是从当前大模型算力建设、模型开发和应用落地的实际需求出发,开发出全栈全流程的智算软件栈OGAI,提供完善的工程化、自动化工具软件堆栈,帮助更多企业顺利跨越大模型研发应用门槛,充分释放大模型创新生产力。

快速进化的人工智能正在呈现越来越强的泛化能力,但技术进步的不可预测性也在随之增强。为此,我们能够依赖的只有不断的创新,通过政策驱动、应用导向、产业构建等多重手段相结合,不断夯实大模型基础能力和原始创新能力,积极适应人工智能的快速迭代与产业变革,切实有效的解决好大模型算力“买不起、建不了、算不好”的难题。