北京2024年5月10日 /美通社/ -- 近日,浪潮信息发布为大模型专门优化的分布式全闪存储AS13000G7-N系列。该系列依托浪潮信息自研分布式文件系统,搭载新一代数据加速引擎DataTurbo,通过盘控协同、GPU直访存储、全局一致性缓存等技术为AI大模型数据归集、训练、数据归档与管理等阶段提供强大存储支撑能力,助力用户加速大模型系统的创新及应用落地。

化解大模型时代的存储挑战 构建坚实的数据存储底座
大模型已经成为驱动数字经济深度创新、引领企业业务变革、加速形成新质生产力的重要动能,随着大模型参数量和数据量的极速膨胀,多源异构数据的传、用、管、存,正在成为制约生成式AI落地的瓶颈之一,用户亟需构建更加高效的存储底座。在数据准备阶段,在规模大、来源广泛、格式多样的原始数据中,筛选和清洗出利用于训练的高质量数据常会耗费大量时间;在模型训练阶段,海量小文件数据加载、Checkpoint数据调用对IO处理效率提出严苛要求;模型训练之后,多个数据资源池无法互通、海量冷数据归档带来较高的数据管理复杂度。
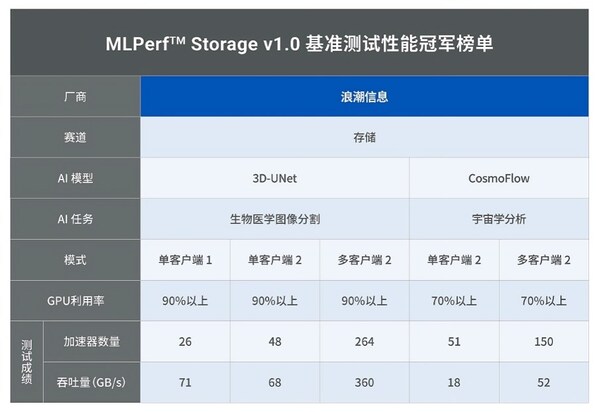
作为率先在业界提出分布式融合存储的厂商,浪潮信息聚焦行业客户的大模型落地需求与核心痛点,基于NVMe SSD研发出高效适配和优化的分布式全闪存储AS13000G7-N系列。硬件方面,AS13000G7-N是一款2U24盘位的全闪存储机型,搭载英特尔®至强®第四、第五代可扩展处理器,支持400 Gb 网卡,同时每盘位可配置15.36TB 大容量NVMe SSD。软件方面,通过集群控制服务将N个节点联成一套具有高扩展性的文件系统;通过分布式元数据服务提升海量小文件读写性能;通过数控分离架构,实现东西向网络优化,降低IO访问时延,提升单节点带宽。在软硬件协同创新下,AS13000G7-N充分满足大模型应用在存储性能和存储容量方面的严苛需求。
具体来说,在数据准备阶段,通过多协议融合互通技术,面对多份、多种协议的数据,存储底层仅保留一份数据,实现数据共享免搬迁;在模型训练阶段,通过大小IO智能识别和缓存预读技术快速保存和恢复checkpoint(检查点)文件,实现TB级训练数据Checkpoint读取耗时从10分钟缩短至10秒内,大幅提升训练过程中数据加载速度;RDMA/RoCE网络连接技术和数控分离架构的设计,实现东西向数据免转发,极限发挥大模型训练中硬件网络带宽性能;基于盘控协同架构,网络数据直通NVMe SSD,进一步提升单盘带宽;在数据归档与管理阶段,AS13000G7-N提供了多元异构存储的统一纳管能力,保障数据资产高效存储与管理,大幅提升存储资源的利用率且最大化数据基础设施投资回报比。

DataTurbo数据加速引擎,全力保障大模型高效训练
在大模型的数据应用全流程中,要想使训练效率达到极致,减少不必要的资源浪费,训练阶段的数据读写性能成为重中之重。而想要提升算力利用率、降低模型训练成本,必须要在数据存储性能上进行创新。
AS13000G7-N系列具备强大的端到端性能优化能力,这也是模型训练阶段最为核心的考量因素。浪潮信息基于计算和存储协同的理念,依托自研分布式文件系统构建了新一代数据加速引擎DataTurbo,在缓存优化、空间均衡、缩短GPU与存储读取路径等方面进行了全面升级。"
AS13000G7-N能够通过对大小IO的智能识别,进行分类治理,小文件采取聚合的操作,大文件采取切片的操作,所有数据以大小均衡的模式保存到全局缓存中,实现小文件性能提升5倍,大文件性能提升10倍。在模型训练中断后,从Checkpoint恢复数据过程中,AS13000G7-N通过缓存预读技术,提前识别数据的冷热程度,加速了重复样本数据的读取,训练加载速度提升10倍。无论是读操作还是写操作,AS13000G7-N采取了字节级(Byte)分布式锁机制,粒度是主流并行文件系统锁机制粒度的几十分之一,确保多个节点访问共享资源时能够安全、有序地进行操作,从而保持训练数据的强一致性和训练质量。
AS13000G7-N搭载了浪潮信息自主研发的分布式并行客户端技术,相比通用私有客户端,卸载了独立的元数据,实现了元数据和数据节点的高效统一部署,有效提升存储的并发能力,充分利用训练节点网卡的带宽,让GPU算力得到完全释放。同时在存储端,相较于业界主流的文件系统需要在磁盘之上构筑一层文件协议,AS13000G7-N能够直接对裸盘的空间进行均衡排布,并在管理层面设计了智能空间预分技术,能够结合用户前端算力节点数量、训练模型的数量,对存储空间分配进一步进行智能策略预埋。这套组合拳能够使AS13000G7-N在空间利用率达到95%高水位时,依然可以平稳输出强大的性能。在模型训练的空间损耗上,AS13000G7-N相较传统方案,将损耗率降低了85%左右,充分保护了客户在大模型存储上的投资。
当大模型参数在百亿级别,GPU对存储资源的调用效率往往差别不大。但随着大模型从单模态走向多模态,数据量指数型增长,训练效率随之要求更高。从数据层面来看,AS13000G7-N具备和GPU直通的能力,数据流不经过客户端缓存,直接到达存储底层文件系统,缩短GPU与存储的读取路径,这项技术能够使存储读写带宽翻倍,大模型训练加载时间缩短50%。随着万卡万亿参数模型时代的到来,GPU直通存储高效提升数据读写访问的能力将是大模型训练的标配。
通过上述技术创新,分布式全闪存储AS13000G7-N凭借领先的性能和管理优势,能够帮助用户加速大模型的数据归集、提升模型训练效率、简化海量异构数据的管理,从而推动业务智能化变革。浪潮信息将借助AS13000G7-N等存储产品,与合作伙伴加快在场景化方案定制、市场拓展等方面的创新,助力用户构筑人工智能时代最佳数据存储底座。