北京2022年12月19日 /美通社/ -- 浪潮信息副总裁、浪潮AI&HPC产品线总经理刘军在近日举行的量子位“MEET2023智能未来大会”上发表了主题演讲《AI新时代,智算力就是创新力》。
在该大会公布的“2022人工智能年度评选”榜单上,浪潮信息获评为“2022年度人工智能领航企业”,刘军获评为“2022年度人工智能领军人物”。

以下为刘军在MEET2023智能未来大会的演讲实录:
为什么说智算力就是创新力?
当今在人工智能前沿领域的大模型,就是在智算算力驱动下重大创新的典型,比如GPT-3,浪潮“源1.0”等等,这些大模型发展的背后是算力的极大支撑。
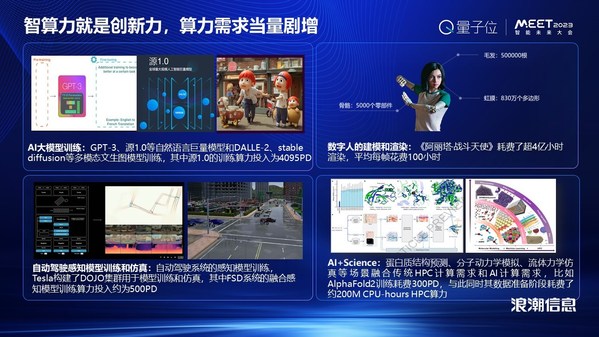
我们提出用“算力当量”来对AI任务所需算力总量进行度量,单位是PetaFlops/s-day也就是PD,即用每秒千万亿次的计算机完整运行一天消耗的算力总量(PD)作为度量单位。一个任务需要多少PD的计算量,就把它视为这个任务的“算力当量”。GPT-3的算力当量是3640个PD,源1.0是2457亿的参数的大模型,它的算力当量是4095个PD。
当前元宇宙非常关注的数字人的建模和渲染方面,如果要做一个栩栩如生的人物形象的创建和渲染,以《阿丽塔:战斗天使》来举例,它平均每一帧需要花100个小时来渲染,总共这部影片的渲染计算使用了4.32亿小时的算力。
在自动驾驶领域,特斯拉创建了DOJO的智算系统,用于感知模型的训练和仿真。它的FSD全自动驾驶系统的融合感知模型,训练消耗的算力当量是500个PD。
在备受关注的AI+Science领域、蛋白质的结构预测、分子动力学的模拟、流体力学的仿真,它不仅融合了传统的HPC计算也融合了当今的AI计算。比如说,经常被提及的AlphaFold2,它的训练消耗的算力当量是300个PD。与此同时,为AlphaFold2训练所做的数据准备,需要花费200M CPU-hours HPC算力。
我们可以确切地认识到,今天在AI领域的众多创新背后离不开智算力的支撑,可以说智算力就是创新力。
接下来和大家来分享当前智算发展的三个重要的趋势:算力多元化、模型巨量化以及元宇宙。
算力多元化需要软硬一体的支撑平台
第一,算力多元化。Henessy和Patterson在几年前的《计算机架构的新黄金时代》中提出了特定领域的体系架构Domain Specific Architectures(DSAs)的概念,这也可以用来解释为什么今天我们会看到这么多的多元算力芯片。
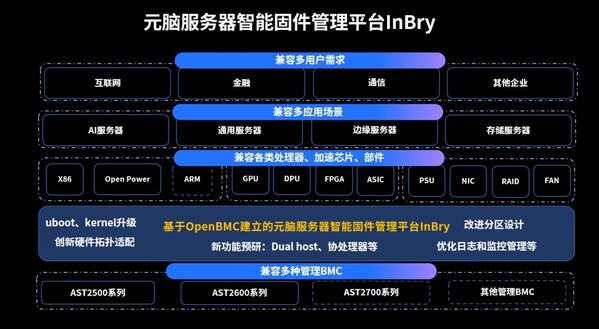
在中国,市场上有十几种的CPU芯片,有将近一百种AI算力的芯片。为什么会有这样的需求?今天算力的应用场景是多元化的,不同的场景需要不同的计算精度类型和计算特征。比如说,高性能计算里面可能会需要FP64双精度计算,AI训练需要使用数字范围更大、精度低的16位浮点计算,AI推理可以使用INT8或者INT4格式。而为适应这些计算的特点,需要我们引入多元的芯片来进行支撑。如何从软件和硬件上来应对这样的挑战?浪潮信息认为,重点是从系统的硬件平台和软件角度来进行相应的创新支撑。
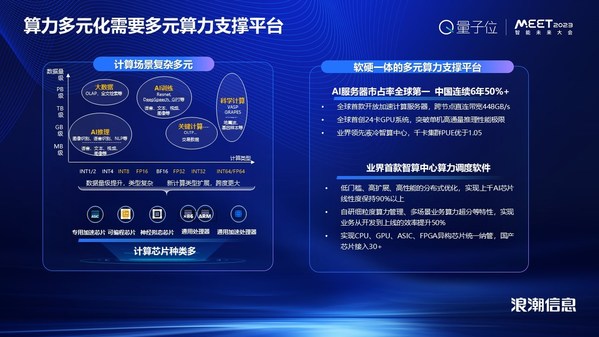
首先是在硬件方面的系统支持,当今AI计算用的非常多的还是采用英伟达GPU的AI服务器。但是对于其他品牌的AIPU来说,要用什么样的一个AI服务器系统来支撑呢?浪潮信息打造了全球首款开放加速的AI服务器,在一个系统里能够支持8颗国内最高性能的AI芯片进行高速互联,从而能够完成大规模的模型训练所需要的算力。芯片之间使用了开放加速的接口标准,芯片间可以进行高速通信。今天,这个系统已经可以支持多个品牌的国内最高端的GPU和AIPU,并且已经在众多的客户场景里面实现了落地。同时,它还支持先进的液冷技术,使得我们构建的AI算力集群的PUE会低于1.1。
作为智算中心的核心,如何来调度多元的算力?这是一个平台软件方面的挑战,浪潮为此推出了业界首款智算中心算力调度软件AIStation,实现了对异构AI芯片进行标准化与流程化管理,不仅能够充分发挥多元异构芯片的性能潜力,并且能够提升智算中心的整体效能。从基本的接入适配到业务应用在异构算力的使用优化,AIStation提供了完备的工具与解决方案,与传统开源方案相比,芯片接入稳定性方面提升30%,减少接入工作量90%以上。标准化、流程化也使得AIStation在芯片管理种类上达到了业界前列,已经支持了30多款国内外最顶尖的AI芯片,包括X86和ARM等CPU芯片、FPGA芯片,也包括今天应用非常广泛的GPU和AIPU,例如像英伟达的GPU系列,以及各类国产AIPU等等。
我们做了众多的实践落地,位于宿州的淮海智算中心采用全球领先的“E级AI元脑”智算架构,通过开放多元的系统架构,在底层基础设施层支持通用处理器、通用加速处理器、专用芯片、可编程芯片等,通过AIStation实现了异构算力的调度,提供FP64、FP32、FP16、INT8等多种精度的计算类型支持,并支持国内外主流的深度学习的框架、数据库、数据集以降低用户的学习成本。
大模型成为AIGC算法引擎
第二,大模型。大模型正在成为AIGC的算法引擎,今天大家看到的DALL・E或者Stable Diffusion的背后都是大模型在驱动。大模型使得AI从五年前的”能听会看”,走到今天“能思考、会创作”,下一步甚至于到“会推理、能决策”的进步。但是我们知道大模型带给我们的是在算力方面巨大的挑战。如何能够把大模型的能力交付到众多的中小企业中,帮助他们实现智能化的转型,是我们今天要去解决的重要课题,所以在这方面我们认为Model as a Service(MaaS)是比较好的一种方式。
今天,在大模型的能力加持下,AIGC,包括文本生成、文生图以及虚拟数字人等应用都会快速的进入到商业化阶段。
“源1.0”是浪潮去年推出的中文语言巨量模型,拥有2457亿参数,在众多的评测里面表现出了非常优异的成绩。团队围绕深度学习框架、训练集群IO、通信开展了深入优化,构建了面向大模型的软硬件协同体系结构,训练平台的算力效率达到45%,这遥遥领先于GPT-3、MT-NLG这样的大模型。同时,通过在AI编译器与深度学习推理框架上的优化,“源”已经实现了对多元AI芯片的支持。
下面分享几个基于“源1.0”构建的实际应用案例:
第一个案例是AI剧本杀。剧本杀是大家比较熟悉的游戏,一位开发者基于“源1.0”构建了一个AI角色来和人类玩剧本杀,玩到最后其他人类玩家都很难察觉到自己是在和AI一起玩剧本杀,因为AI在这里面所表现出来的场景理解能力、目的性对话能力是我们在传统的AI算法上面很难见到的。目前项目已经在GitHub上开源,大家感兴趣可以尝试。
第二个案例,上海一个开发者群体基于“源1.0”构建了数字社区助理,类似于给我们的居委会打造了一个教练员,通过让AI模拟来居委会咨询的居民,提升社区工作者应对居民突发状况服务的能力,这种将大模型反向应用于教培领域的案例给AI发展带来了更多想象空间。

最近,大家都在讨论ChatGPT,简单来说它就是基于大模型的面向长文本、多轮对话的AIGC应用。其实我们基于“源1.0”也开发了公文写作助手。现在大家希望有个助手来协助写总结报告、学习体会,所以我们希望打造一个写作助手来帮助大家进行长本文创作。其中,我们突破了可控文本内容生成技术,解决了长文本内容偏移问题,生成文本的语义一致性高达96%。这样的优化使得我们的中文写作助手能够带来非常惊艳的效果,目前我们的产品处于内测阶段,欢迎大家来申请使用。
我们把“源”大模型应用在浪潮自己的业务上,赋能自身业务智能化转型。浪潮信息是中国最大、全球第二的服务器厂商。我们拥有一个覆盖非常广泛的客户服务系统,传统的智能客服更多是基于规则和提炼的知识来构建的问答系统,这样的问答系统大部分情况下是不能帮客户满意地解决问题的。今天基于“源1.0”构建的浪潮信息智能客服可以进行长文本的内容生成,能够持续地多轮对话,同时非常重要的是它不仅仅是基于知识规则而构建的问答系统,它可以自己去阅读和服务器相关的产品技术文档,我们说它可谓是服务器的“服务大脑”,在它的支撑下,浪潮信息的客户服务效率得到了大幅的提升,这个项目荣获了《哈佛商业评论》鼎革奖,即年度新技术突破奖。
元宇宙需要强大的算力基础设施
第三,元宇宙。大家可能会惊奇元宇宙需要算力吗?我们告诉大家,元宇宙非常需要算力。元宇宙的构建有四个大的作业环节,协同创建、高精仿真、实时渲染、智能交互,每一个环节上面都需要大量算力做支撑。比如说,在高精仿真的阶段,要实现元宇宙场景中逼真的、符合物理定律的仿真,不仅需要AI计算,同时还需要HPC算力。在图形渲染环节,不仅传统的光线追踪、路径追踪等图像渲染算法需要大量算力,当今基于AI的DLSS等算法也需算力支撑。到了最后的智能交互环节,今天所看到的数字人、多轮的语言交互等等,它背后都是基于算力才得以实现,这就是为什么说元宇宙需要强大的算力支持。
今年浪潮信息推出的MetaEngine元宇宙服务器就是为了应对这样的算力挑战,有兴趣的可以看下我们如何基于MetaEngine来创建虚拟数字人和数字孪生的全过程。

为了推动了元宇宙的快速落地,上个月青田人民政府和浪潮信息和我们合作伙伴谷梵科技一起,签约建设国内首个元宇宙算力中心,用于支撑在青田、浙江乃至于长三角在元宇宙的数字空间创建、数字产业发展,支撑数字经济、数实融合的发展。
我的演讲到此结束。谢谢大家!