北京2022年4月27日 /美通社/ -- 随着互联网、5G、IoT等飞速发展,数字化、智慧化的建设对算力提出更高的要求,数据中心向着规模化、集约化、绿色化不断演进,根据ResearchAndMarkets 《全球数据中心托管服务市场机遇》报告显示,超大规模数据中心预计将从2019年的509个增长到2025年的890个,这将改变数据中心建设和使用的方式,数据中心规模不断扩大,大型数据中心服务器数量已经达到了10万以上的量级,这意味着对运维的难度、人力、成本、专业性都提出了更高的要求,企业数据中心的运维压力面临着前所未有的挑战,打破传统运维方式,打造"监、管、控、防"智能化的运维是解决问题的关键。
什么是智能运维?
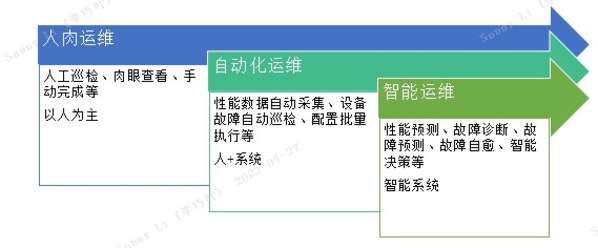
首先,要了解数据中心运维的发展历程,它主要包含三个阶段:人肉运维、自动化运维和智能运维。
所谓人肉运维就是指 -- 在早期,大部分数据中心的运维工作是由运维工程师手工完成。服务器运行状态,全靠运维工程师每日肉眼查看,进行问题定位与解决,每位工程师可以运维的上限约为400台设备。这种低效的运维方式,在数据中心服务器增多和人力成本逐渐增高的时代,是难以维继的。
所以自动化运维便应运而生,由运维工程师根据运维经验编写脚本,进行批量设备巡检,后期发展成基于任务的设备巡检,这便是自动化运维的早期方式。这大大提升了发现异常设备的效率,降低了运维成本。但是,面对故障根因、故障预测、性能趋势和控制决策,自动化运维却力不从心。
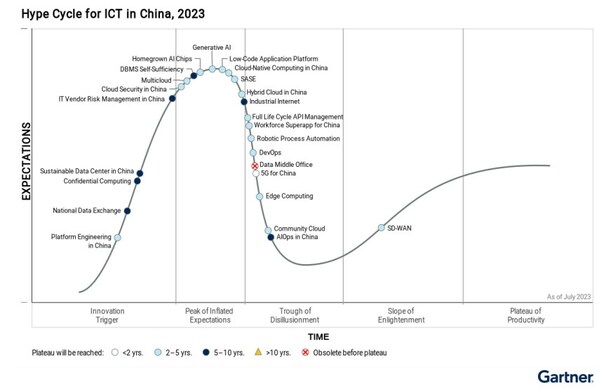
根据Gartner发布的《2021年中国ICT技术成熟度曲线报告》显示,AIOps市场将持续增长并影响整个IT运营管理市场,报告预计未来2-5年内AIOps将进入成熟期并会帮助企业大幅节约成本。从服务器运维的角度来分析服务器智能运维,目标就是通过对带外信息(配置信息、状态信息、性能信息、日志等)和带内信息(配置参数、性能信息、日志信息)进行采集,利用机器学习的方式来解决上述问题,提高系统预警能力和稳定性,降低运维成本,提高运维效率。
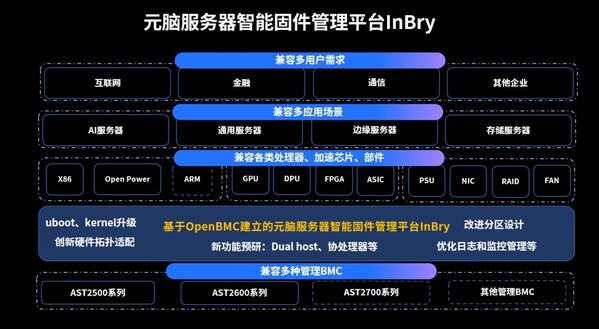
浪潮信息打造智能化的物理基础设施管理平台(ISPIM)
浪潮信息物理基础设施管理平台ISPIM,通过对数据中心IT设备的7*24h纳管监控,实现在异常检测、故障诊断、故障预测、故障自愈、性能预测等多维度的智能化运维。
服务器运维中,最根本的是对于异常的检测,常见的是对状态指标、性能指标和日志数据三大数据的检测。
状态指标:当服务器的状态出现异常时,浪潮信息ISPIM管理软件通过主/被动方式对服务器的异常进行聚合,防止重复告警和误报,同时对同时刻多告警进行根因定位,防止告警风暴,产生告警麻痹。
性能指标:在性能指标检测方面,传统手段是设置阈值,但常常因为某一时刻产生噪点数据而发生误报,通过重复次数,阈值抖动范围和自学习数据密度分布等方案,便能够解决噪点数据产生的99%的告警误报;但面对周期性变化的数据却无法进行动态调整,也会产生误报的情况,大大降低告警的准确性。浪潮信息ISPIM管理软件通过AI优化,针对性能数据进行时域、频域、能量等变化进行动态分析,采用LSTM和随机森林两种方案进行预测,告警准确性达到98%。
日志数据:日志一般是半结构化的数据,根据日志级别产生告警,准确性不够并且只能检测到已知和确定模式的异常。浪潮信息ISPIM管理软件拥有4000+运维专家资源库,帮助实现服务器故障快速诊断,同时在日志智能故障诊断方面,会将采集的日志进行重新编码,不断加深对深度学习、LSTM等算法的研究、实践应用,实现从多个维度对服务器异常进行分析,异常检测准确率高达99%。
为进一步提高运维效率,浪潮信息ISPIM管理软件除了对日志的故障诊断之外,还会对系统宕机后的数据进行深入的剖析,便于问题快速定位,提高效率。
通过对采集的海量数据进行分析,浪潮发现服务器的宕机通常是发生了CPU MCE(Machine Check Exception)故障,MCE来源一般来说有两种,一种是CPU本身故障,一种是来自CPU外部的部件。浪潮信息ISPIM管理软件通过带外收集服务器CPU寄存器数据,基于MCA(Machine Check Architecture)技术架构,通过定位CPU触发源、分析MC Bank、解析CSR、MSR寄存器,实现故障原因的确认以及故障部件的精准定位,并根据浪潮信息专家经验库对故障问题给出专业的解决方案,从而提升运维效率。
据统计显示,在数据中心中由内存、硬盘造成的故障占比超过50%以上,其主要原因在于硬盘、内存保有量较大,生命周期相对较短,使用率较高等。当内存或硬盘产生故障时,极容易发生严重宕机事故。
对于内存而言,内存产生的CE(可纠正错误),可以通过ECC(Error Correcting Code)机制进行纠正,但是频繁的CE往往会产生UCE(Unchecked Error),一旦产生UCE,往往会导致系统宕机。因此,预测内存故障即可转化为预测UCE,浪潮信息ISPIM管理软件对内存CE,通过多个维度统计分析,从CE总频率、内存固定物理地址CE频率阈值、固定Cell CE频率阈值、CE在Column分布范围及频率阈值等维度统计,获取UCE与CE关联关系,从而预测UCE。
而对于硬盘,在数据中心中大多存储阵列会采用一些冗余机制,但是这只能保证有限硬盘失效的场景,一旦故障盘数量超过RAID冗余的极限之后,很可能造成系统宕机或者数据丢失的风险。浪潮信息ISPIM管理软件通过对SMART(Self-Monitoring Analysis and Reporting Technology)标准进行分析,获取硬盘故障预测的关键数据特征,基于模型算法进行训练,优化模型算法,输出为推理算法模型,通过SMART指标及硬盘运行日志,预测风险盘。同时当硬盘预测达到换盘指标时,可支持换盘操作。
通过这些技术优化,浪潮信息ISPIM管理软件可以实现对内存和硬盘的故障预测,大大提高系统稳定性。
浪潮信息ISPIM管理软件在针对故障自愈方面,可以支持内存故障自动隔离,在操作系统层面,结合MCE(Machine Check Exception)日志数据信息,基于CE故障信息,通过虚拟内存故障Page诊断算法,确定内存故障Page,并在操作系统内核执行Page Offline,通过虚拟内存技术,隔离对故障内存区域的访问,实现内存故障隔离。在物理内存层面,基于CE故障信息,通过物理内存故障诊断算法,利用SPPR(Soft Post Package Repair)、HPPR(Hard Post Package Repair)对物理内存故障Row进行隔离,在技术上实现对故障内存的永久性隔离,提高操作系统的稳定性和可靠性,从而保障业务的稳定可靠运行。
性能预测是指对服务器的性能数据,经过ARIMA、指数平滑、LSTM、Prophet等智能算法,能够感知系统在未来几个小时、几天或者一年的数据的走势、增长量或者周期性变化等。浪潮信息ISPIM管理软件凭借自研性能分析核心组件,可支撑上万台服务器同时进行秒级性能数据的监控与告警,帮助运维人员实时掌握设备的性能状况,实现对磁盘寿命、容量预测,准确率达到99%。
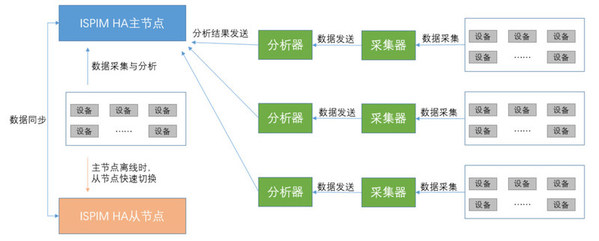
浪潮信息物理基础设施管理平台ISPIM(Inspur Physical Infrastructure Manager),具备资源管理、故障监控、性能监控、能耗管理、自动部署、报表统计、网络拓扑和3D视图等功能,可同时对数万台不同品牌服务器、存储、网络设备等设备进行统一监控、运维、告警管理,运维效率提升2倍,基于浪潮信息故障专家库的大数据规则故障诊断功能,可将故障诊断准确率提升到93%,并且可在快速处理故障的同时极大程度降低数据泄露风险,帮助用户打造无人值守数据中心,提高运维效率并降低运维成本,保障数据中心安全、可靠、稳定的运行。