北京2021年10月29日 /美通社/ -- 10月26日,在北京举行的2021人工智能计算大会(AICC 2021)上,浪潮人工智能研究院正式发布“源1.0”开源开放计划,这一全球最大中文巨量模型将以开放API、开放数据集、开源代码等多种形式为业界提供开放合作,人工智能相关高校和科研机构、产业伙伴及智能计算中心用户可通过“源1.0”官网air.inspur.com提出申请,经审核授权后即可基于“源1.0”模型探索算法创新以及开发各类智能化应用。

浪潮宣布全球最大中文AI巨量模型"源1.0”开源开放计划
“源1.0” 开源开放计划将首先面向三类群体,一是高校或科研机构的人工智能研究团队,二是元脑生态合作伙伴,三是智能计算中心。面向第一类群体,“源1.0”将主要支撑在语言智能前沿领域的算法创新和方向探索;面向第二类群体,“源1.0”将主要支撑元脑生态伙伴开发行业示范性应用,如智能文本服务、语言翻译服务、内容生产服务等等,探索语言智能产业落地的“杀手级应用”;面向第三类群体,“源1.0”将作为算法基础设施,与智能计算中心算力基础设施高效协同,支撑AI产业化和产业AI化发展。
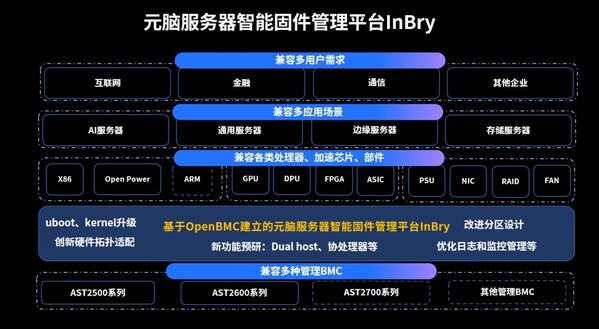
“源1.0”开放开源计划项目包含开放模型API,开放高质量中文数据集,开源模型训练代码、推理代码和应用代码等。同时,浪潮人工智能研究院将和合作伙伴一起,共同开展针对国产AI芯片的“源1.0”模型移植开发工作。
为更好的支撑“源1.0”的开源开放计划,浪潮人工智能研究院将加强模型API和平台生态构建,开发支持高并发、高速推理的多种API接口,以支持各类用户对模型或功能的不同请求方式。同时,浪潮人工智能研究院也将大力运营“源1.0”开源开放社区,建立完善的开发反馈机制并加快模型迭代。
浪潮信息副总裁、AI&HPC产品线总经理刘军表示:“巨量模型应该成为普惠性的科技进步力量,让行业用户甚至是中小用户也能使用巨量模型寻求深度创新,促进业务可持续健康发展,这是浪潮开源开放‘源1.0’的初衷。我们希望与更多的产、学、研、用单位和开发者一起,从技术创新、场景融合、应用开发等各个维度,共同促进巨量模型的健康发展与产业落地。”
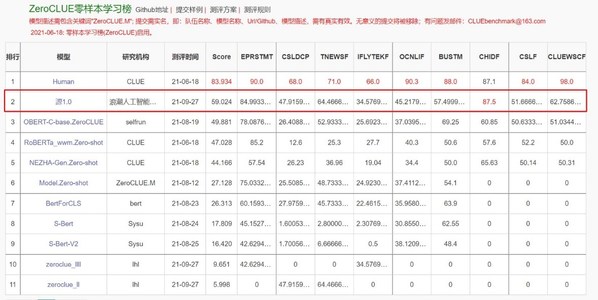
“源1.0”是全球最大规模的中文AI巨量模型,其参数规模高达2457亿,训练采用的中文数据集达5000GB,相比GPT-3模型1750亿参数量和570GB训练数据集,“源1.0”参数规模领先40%,训练数据集规模领先近10倍。 “源1.0”在语言智能方面表现优异,获得中文语言理解评测基准CLUE榜单的零样本学习和小样本学习两类总榜冠军,测试结果显示,人群能够准确分辨人与“源1.0”作品差别的成功率已低于50%。
在AICC 2021大会现场,参会人员与“源1.0”进行实时互动,根据互动者给出的主题或者上联,“源1.0”会迅速作出诗歌或者对出下联。众多参会者在现场体验“源1.0”的诗词创作能力,体验者表示,如果不是亲身体验,肯定看不出来诗歌是AI模型创作的,“重要的不仅能押好韵,而且更能写出中文诗的美妙意境。”

AICC参会者排队体验“源1.0”巨量模型的文学创作能力
浪潮人工智能研究院透露已启动新的巨量模型“源2.0”的开发工作,“源2.0”的开发会更注重协同创新,将与业内合作伙伴联合展开前沿探索。