深圳2021年5月26日 /美通社/ -- 近日,澳鹏Appen凭借业界高度认可的“人工智能辅助数据标注平台”在2021第二届深圳(国际)人工智能展上斩获“优秀产品奖”。活动现场,澳鹏Appen(中国)高级研发总监蒋孟杰接受CSDN记者邓晓娟Carol的专访。访问原文如下:
高级研发总监蒋孟杰接受CSDN记者专访")
澳鹏Appen(中国)高级研发总监蒋孟杰接受CSDN记者专访
2021年5月20日~23日,由深圳市科学技术协会、深圳市商务局、深圳市福田区人民政府共同指导,深圳市科技开发交流中心、深圳市人工智能行业协会联合主办的2021第二届深圳国际人工智能展开幕式暨智能制造创新高峰论坛在深圳会展中心(福田)圆满举行。
深圳市科协主席蒋宇扬在大会致辞中指出:“人工智能既是引领未来的战略性技术,也是新一轮产业变革的核心驱动力”。诚然,在当今社会发展中,人工智能技术所占据的地位已是举足轻重。
#01 人工智能到底“智不智能”?
正如蒸汽时代的蒸汽机、电气时代的发电机、信息时代的计算机和互联网,人工智能正在成为推动人类进入智能时代的决定性力量。
然而回溯过往,我们会发现热门如人工智能技术,在发展的过程中也未必“星途坦荡”的。在人工智能历史上曾出现过“三次高潮”:
在世纪50年代~80年代,由于许多应用难题无法解决和基础研究知识难以突破而没有达到人们预期的成果和推进。从起步-应用-低迷-平稳-蓬勃发展,人工智能的道路上充满着未知的探索,道路曲折起伏。
如今,我们正处于信息时代到智能时代的过渡期中,人工智能作为主要的推动因素,让全球产业界充分意识到人工智能技术引领新一轮产业变革的重大意义,纷纷转型发展。而“新基建”的提出与疫情的影响,让2020年成为人工智能史上的一个重要拐点。如果说在2020年之前人工智能技术还在摸索着落地应用场景,那么在2020年开始,人工智能已经加速进入人们的生活。
只是,在人工智能飞速发展的今天,人们的需求也不断在上升。对于人工智能企业或转型企业而言,如何跟上时代是首要考虑的问题。但落到群众当中,落到人们的衣食住行当中,人工智能到底“智不智能”,才是人们所关注的重点。
企业想要把AI技术/产品真正落地,真正做出“好的人工智能”,首先不能让AI技术/产品只停留在实验或原型阶段,AI模型的高质量训练是重中之重。
那么,AI模型如何才能得到高质量训练?在AI项目部署的生命周期当中,有哪些可优化的地方?数据在这个过程中起到了哪些关键性作用?企业在转型路上又该如何挑选数据平台/相关服务商?带着这些问题,CSDN记者对话了知名人工智能数据服务商澳鹏Appen的高级研发总监蒋孟杰。
值得一提的是,澳鹏在2021第二届深圳国际人工智能展开幕式暨智能制造创新高峰论坛中斩获“优秀产品奖”,也曾连续六年入围德勤高科技成长50强企业(澳大利亚)、维科杯·OFweek2020人工智能行业优秀产品应用奖(澳鹏人工智能辅助数据标注平台)、CIAI 2020年度中国人工智能行业“十大创新力企业奖”等奖项。

GAIE2021第二届深圳国际人工智能展 “优秀产品奖”
这样一个专注于人工智能数据标注的行业领军服务商,是如何用数据推动人工智能技术与产品的?一起来听听蒋孟杰的真知灼见。
#02 “用AI的方式服务AI”
蒋孟杰在加入澳鹏之前,曾在国际知名电商公司eBay任职,主要专注于搜索引擎搜索算法领域。大约在11年前,也就是2010年互联网蓬勃发展的阶段,就与澳鹏合作利用人工审核商品和搜索关键字之间的相关性来做相关度算法以及线下算法评测平台,在该领域有着丰富的经验及思考。
2019年3月加入澳鹏后,蒋孟杰负责中国区技术团队的研发、及全球部分模块研发等。他所带领的团队致力于打造全流程的数据平台,包含数据采集,数据标注和数据管理。另外,针对成熟且复杂的场景开发更加高效的标注工具,如自动驾驶、人脸关键点、长语音转写等。
蒋孟杰表示,越来越多的企业正在走向AI的道路,与此同时,对训练数据也有了更高的要求。AI模型想要真正落地,需要大量高质量的、安全无偏差的数据,澳鹏的目标是帮助企业能够把AI技术/产品真正的落地,,而不是只停留在实验或者原型阶段,将采标流程一体化。

深耕行业20多年澳鹏,在数据采集和数据标注的过程中,积累了大量的行业经验和案例,同时也拥有了自己先进的技术、资深的项目管理和标注团队,并且提出“用AI的方式服务AI”的理念。
澳鹏如今拥有一个数据科学家团队,一方面会在服务企业之前了解场景,设计如何采集数据/标注数据能真正帮助到企业成功训练模型,以结果导向。另一方面也把AI技术应用到整个服务的流程中。用AI模型进行以下工作:

澳鹏人工智能辅助数据标注平台-多轮质检
#03 技术不能闭门造车
在人工智能数据标注领域,纯自动化标注是不现实的,逻辑上也不成立。“你用算法生成的数据去训练另一个算法,最完美的情况下,也就是训练出跟之前一模一样的一个算法。”蒋孟杰说道。但也不能只做纯手工标注,传统的数据标注是个纯人力密集型的任务,对于技术从业者而言是非常诱人的领域,因为稍微有一点技术的引入,就能给企业降本增效。
在平台的设计理念和系统架构上,蒋孟杰有着自己的思考。业务在设计之初就引入AI中台的概念, 围绕着AI中台为业务赋能,引入Apache Pulsar作为数据湖,围绕这个核心组件设计了灵活的标注任务的分发和工作流管理。因为业务数据都落地Pulsar里面,借助Pulsar的高吞吐量,可以多次重复高效得消费这些数据进行快速且松耦合得进行业务扩展,比如结合 Flink 做实时进度/工作量/质量的报表计算用来做项目管理,也可以对标注员进行画像,可以实时进行反欺诈监测,另外也可以对在线标注数据实现边标注边训练,同时反过头来辅助标注等。
澳鹏在全球市场已经累积了25+年的行业经验,进入中国市场后,澳鹏借鉴了海外的平台实践,在中国独立自主打造了适合国内行业特点的高精度AI数据服务平台。那么,中国区的技术和产品方面如何与其他地区并进?迭代过程又是怎样的?
蒋孟杰认为,产品迭代一定要跟随业务发展一起锚定的。在平台设计和技术架构搭建初期,事先做好技术的总体架构设计,在此基础上做未来的发展规划。同时,要确保团队成员的目标一致,再定期讨论调整优先级。在刚起步的时候,每个迭代只能完成MVP,非核心的功能会提供功能上的兼容支持,在真正的使用过程中,这些未被产品化的功能使用起来相当痛苦,比如招人的时候,最开始的版本中先专注在标注业务本身,如果要添加,标注员就上传一个Excel文件, 而没有一个完整人员招募和审核流程。
令记者感到意外的是,澳鹏的技术团队并没有闭门造车,关起门来自己解决问题。他们还拥有一支项目支持工程师团队,所有当下平台满足不了的功能,该团队就会准备一次性的脚本和工具进行处理。随后,平台一步步根据优先级把手工处理的任务产品化,平台发布一个版本后及时拿到反馈,然后在下一个版本中进一步提升。所以,在与产品研发团队、项目管理团队、业务团队的紧密合作下,技术/产品迭代速度是相当快的。
#04 人工智能数据与质量决定上层建筑
如果说优秀技术架构与高效迭代是决定一家人工智能数据服务商是否站得稳的关键,那么真正决定它是否走得更远的,就在于产品本身解决问题的能力到底有多强。
在这个问题上,蒋孟杰提出了一个关键点:“AI项目部署生命周期”。
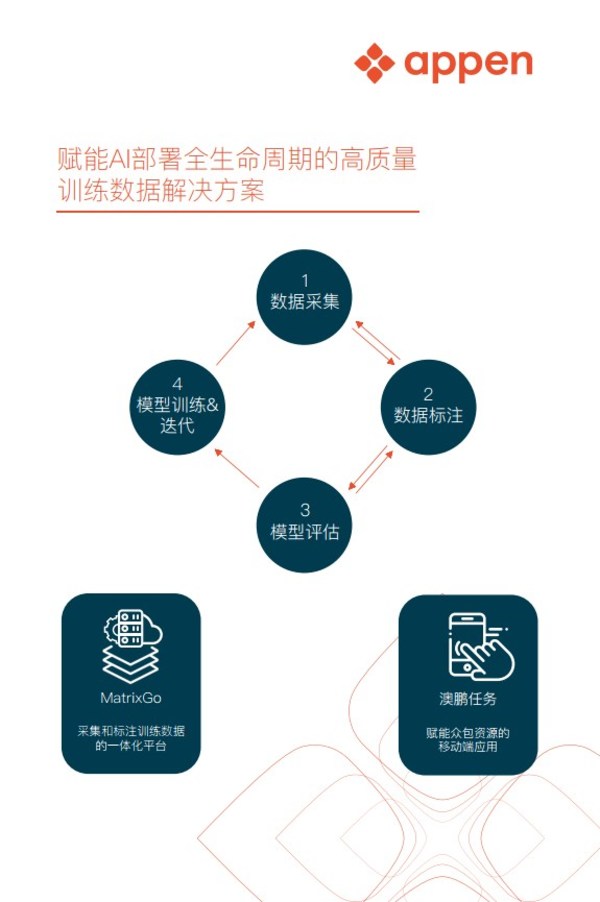
一般 AI 项目部署的生命周期会包含:数据采集、数据标注、数据探索、模型开发、模型发布、定期监控。
那么,数据在这个生命周期里扮演着怎样的角色?澳鹏又解决了哪些问题?蒋孟杰描述数据的重要性时引用了Andrew Ng(吴恩达,人工智能和机器学习领域国际最权威学者之一)的话:成功的 AI 部署, 80%是数据准备(包括数据清洗/数据标注等), 20%是花在模型开发上。而澳鹏在整个生命周期中帮助客户解决数据采集,数据标注, 模型发布后期监控。
除此之外,数据的可用性质量也是澳鹏服务的核心。蒋孟杰打了个比喻:“AI模型就像小孩子,你教给他什么,他便学会什么。如果数据质量很糟糕,那么AI模型学会的也是这些错误。”所以在澳鹏有一整套方案保障数据的质量:
蒋孟杰认为,项目管理是一门艺术,尤其是人工参与的场景,可能会在整个流程中任意环节出现变化。澳鹏的优势在于其针对各个企业的业务进行深度的打磨,融入了自己的高效的项目管理方式以及标注细节优化。

#05 拨开迷雾
CSDN:听说澳鹏正在密切关注自动驾驶领域,那么在自动驾驶领域的数据方面,目前存在哪些挑战?澳鹏又做了哪些解决方案?
蒋孟杰:这个问题可以分为5个部分。
CSDN:每个企业的技术架构与实力不同,对于初创、中型、大型的企业来说,如何选择合适的数据标注平台/相关服务商?其中有哪些不同吗?
蒋孟杰:初创业务场景变化非常快,一般标注需求量不会很大。而且公司没有精力或者资源开发或维护数据标注平台。我们会推荐纯SaaS模式,可以让初创企业快速开启标注,快速试错调整方向。
中型企业已经有较为成熟的业务模式和自有系统,另外也有资源去开发或者运维数据标注平台,会比较关心是否有开放 API 进行系统集成和二次开发,是否有全面的功能。这类企业,我们会推荐混合云部署模式或者私有化部署模式,并且结合我们 Managed Service 进行数据标注。
而一般大型的互联网企业比较早地使用AI 技术,已经自己开发了一些标注平台。在选服务商的时候会特别看重服务商“是否有能力快速得招到大量高质量的标注员、是否标注工具层面会比自己公司的效率更高、数据安全是否有保障”等。这类企业我们也会推荐混合云部署模式或者私有化部署模式,并且结合我们Managed Service 进行数据标注。
CSDN:您认为未来人工智能数据标注领域或该领域的服务商,会有哪些发展趋势?
蒋孟杰:现阶段标注领域鱼龙混杂,价格竞争激烈,其中不乏大量传统人力服务商进入这个领域。随着行业的洗牌,有快速招人能力、拥有大量项目管理经验、有自有平台研发能力的供应商会逐渐脱颖而出。
标注平台会沿着采集和标注一体化方向发展。对很多AI 企业来说,往往同时需要数据采集和标注。比如刚才的例子,采集日常交流语音,采集完以后需要对语音进行文字转写。如果把采集和标注分成两个独立阶段,时间交付周期很长,另外如果标注觉得采集的语音里面完全没法听清,很难及时打回给采集人员重新录制。
另一方面,未来可能会向AI数据中台发展。不仅管理非结构化数据的,也会慢慢延伸到结构化数据的管理。数据标注在整个生命周期中不会是一个独立的存在。如果分裂的多个系统,数据科学家会浪费大量时间在搬运数据上,效率不高,另外也影响创新。如果以集成式的AI数据中台为基础,数据科学家可以开发算法和数据标注互相迭代提升。比如边标注边实时训练模型,效果没法再次提升的时候就停止标注,这个在业界叫主动学习。
原文链接:https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/117256727