北京2021年3月23日 /美通社/ -- 在数字化转型战略持续落地的今天,大数据分析与人工智能已成为各个行业挖掘数据价值、推动业务转型升级的重要方式,但传统的大数据平台与人工智能平台通常彼此独立,构建一种从数据采集、数据预处理到模型训练与推理的高效流程,经常存在基础设施成本高、效率低下等一系列问题。
为了更好解决大数据分析与AI融合在开发和部署方面带来的诸多疑难,浪潮云海Insight产品构建了端到端的智能计算解决方案,旨在将大数据预处理、模型训练、模型推理与现有的数据处理工作流整合起来,基于传统大数据分析平台中的各种框架模型来简化和加速人工智能业务的开发。
这个挑战很严峻:传统分析模式难以高效“回应”分布式端到端数据分析
通常传统的人工智能学习框架与大数据分析平台之间存在断层,人工智能平台由于不具备多元的数据接入及预处理能力,往往依赖外部(大数据平台)预处理过的数据集进行分析;而传统大数据平台也没有更多考量AI因素,自然难以为AI应用提供敏捷、高效的基础设施支持。基于此,一个从无到有的AI应用场景搭建,往往面临如下困难:
打造端到端智能计算解决方案:大数据与AI分析平台要统一
大数据生态中,Apache Spark作为专为大规模数据处理而设计的计算引擎,其本身提供了很多Data Storage支持,可帮助操作者方便读取HDFS、Parquet、Avro和HBase等格式;同时也提供了大量有用的API来完成数据的ETL、特征提取以及数据清洗等工作,还可以利用Spark MLlib完成一些传统机器学习工作等。
而端到端的智能计算组件Analytics Zoo则可将Spark及AI生态中的TensorFlow、Keras 、BigDL等无缝整合到一个集成管道中,透明扩展至资源管理YARN集群,可便捷地将人工智能应用从单机扩展到大型集群,直接处理大规模生产环境中的数据并进行分布式训练或推理,如此看来端到端的智能计算解决方案并不是重新开发各个组件,而是拥抱现有的开源生态。
此外Analytics Zoo 还为开发人员和用户提供了多种分析和人工智能工具,以便更好地为端到端流水线提供支持,主要包括:简单易用的抽象层,例如Spark DataFrame 和 ML 流水线支持、迁移学习支持以及服务 API 的 POJO 式模型等;面向图像、文本和 3D 图像的常用特征工程操作;内置的深度学习模型,例如文本分类、推荐和对象检测;内置参考用例,例如时间序列异常检测、欺诈检测和图像相似性搜索等。

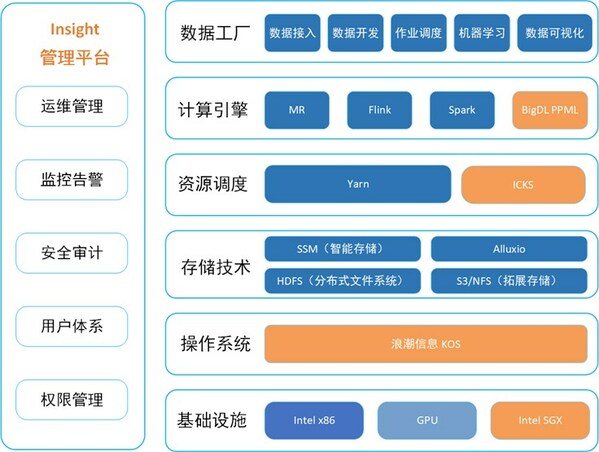
基于Analytics Zoo的统一大数据与AI分析平台
如此形成的智能计算解决方案可以统一大数据与AI分析平台,帮助用户将数据存储、数据处理以及训练推理的流水线整合到一套基础设施中,大幅提升方案的部署效率、资源利用率和系统的可扩展性,以此减少管理以及运维成本。
不断探索:浪潮云海Insight关于“端到端智能计算”的实践
作为面向海量数据存储、计算、挖掘的一站式企业级大数据解决方案,浪潮云海Insight大数据平台从用户需求出发并结合业务场景,对端到端智能计算进行方案性POC及验证,最终在平台中将其技术产品化,包括智能计算相关组件的一键安装部署、可视化运维、交互式智能数据分析体验以及端到端AI流式推理等。
通过简化大数据分析和人工智能的融合开发与部署,构建端到端的数据分析和深度学习应用流水线,进而打造统一的大数据分析和人工智能平台,为用户提供了更优质的体验。

Analytics Zoo在大数据生态中的位置
该方案基于大数据HDFS存储、Spark/Flink等计算以及Yarn资源调度来运行,将数据预处理、模型训练、模型推理等通过Analytics Zoo构建在大数据平台上,提供大数据分析和深度学习应用流水线,避免数据的反复迁移。
用户可以便捷地将AI应用部署到现有的 YARN 集群,在“零”代码更改的前提下将AI应用程序透明地扩展到大型集群,显著节约企业在开发、优化平台等方面的时间与精力,具体可以达到:

端到端的大数据分析和深度学习应用流水线
重要的一点,得益于浪潮云海Insight大数据平台在性能、数据管理、统一运维等方面的优势,以及对于Analytics Zoo的融合,该端到端智能计算解决方案如今能够成功帮助政府、金融和互联网等客户构建高效、敏捷的大数据分析与人工智能平台,助力数字化转型。
伴随大数据与人工智能的蓬勃发展,数智结合已成为大数据技术发展的必然趋势。浪潮云海Insight将从数智深度融合的角度出发,继续加强端到端的大数据分析和人工智能的创新发展,为用户提供更优秀的解决方案。