杭州2018年7月11日电 /美通社/ -- 5月26 日下午,在第二十八期七牛云架构师实践日,李朝光进行了题为《深度学习平台 AVA 及海量资源管理》的实战分享。本文是对演讲内容的整理。
七牛云在深度训练平台里如何管理数据以及 GPU ?
深度训练平台有两个核心,一个是数据管理,一个是计算资源管理。首先提数据管理的原因是,从传统意义上使用数据到深度训练访问数据,会发现一个有趣的问题:数据量已经大到没法管理的地步了。李朝光表示,“比如以往,我们用网盘或搭一个 CEPH,数据一般都是少数几个 T 的级别,但等到真正运作深度训练的时候,会发现跑一个训练,比如图像分类或视频检索训练,就能消耗几十个 T 的空间。怎么有效把这些数据喂到深度训练里?七牛云 AVA 平台的诞生就是要想办法解决这个问题。”
第二是计算资源的管理。这里的计算资源,基本指 GPU,一般来说是 NVIDIA 的 GPU。七牛云实验室里,现在已经有百台级别的 GPU,里面有各种型号,比如 M4、K80,到 P100、V100 都有。这些资源怎么有效地管理、使用,是个难题。七牛云开始是用非常原始的方式,比如抢占方式,后来再慢慢把资源管理模块化、精细化,最后才做到 AVA 这个平台。
七牛云目前围绕的是数据创新服务。但七牛云是做存储起步的,开始是集中在海量(对象)存储,后面进入了机器学习、智能多媒体服务,这些的共用特点是对数据本身的存储管理,比如对象存储。怎么把这么多数据存储起来?怎么高效地把它放在 CDN 里,快速地进行转发?目前七牛云已经基本实现了第一步:把数据有效地管理起来。第二步,怎么发现数据之间的关系?如何根据数据内容做创新?比如一个视频有几千帧,帧和帧之间有什么关系?一个图片,是否属于黄色或暴恐的?七牛云重点做图片、视频的检索、分类,还有人脸识别等。
一个图片过来,不能直接喂到七牛云深度训练系统里,第一步就要做数据处理。之前七牛云有个 DORA 系统,是做图片视频处理的,比如裁减翻转、加水印等。这样可以把数据转换成深度训练需要的格式,然后喂到深度训练系统里,这是目前正在做的一块工作。数据喂进来以后,经过深度训练、视频截帧,发现其中的关系,比如判断图片是不是暴力的、恐怖的,再重新把数据放在结构化存储里。然后反过来做一个迭代。做一个基础模型,内容分发,重新进入系统做一个循环。在这个循环的不停迭代中,不停改变训练的精度,输出一个最终想要的结果。这大体上现在 AVA 平台想做的事情,它的背景就是从传统的内容服务,慢慢过渡到数据挖掘,这部分就是通过七牛云深度训练平台来实现的。
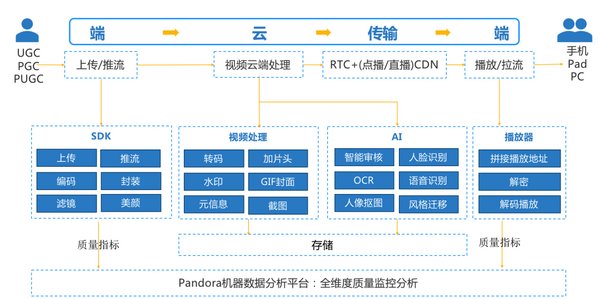
七牛云 AVA 平台的概貌

上面一层是七牛云 AI 实验室主打的方向,是对外部可见的业务层,大部分的业务都是围绕图像、视频定制化,包括鉴黄产品、目标检测等。因为网络上充斥的黄色图片太多,很多客户每天有几千万张甚至上亿张图片存到七牛云。根据国家的法规,这些图片可能会有相当一部分是不适宜在网上出现的。但有时候客户也不知道,不可能靠人把这些图搜出来,我们怎么把这样的图片拎出来?这就需要做一个自动化处理,把图片自动识别。在七牛云这端,把图片清理掉,网站就不会把黄色图片或敏感图片放出去。这是通过深度训练平台,利用算法识别出不同的模型,然后在毫秒级别把图片识别出来。下面一层提供基础的服务功能,即 AVA 深度训练平台。
七牛云 AVA 平台能为大家提供一些什么?
AVA 平台最初是直接服务于算法工程师的。通过引入 CEPH,屏蔽掉存储管理细节,引入 Kubernetes 屏蔽容器管理细节,并把不同的深度训练框架打包到 Docker 镜像中,方便算法工程师使用。算法工程师可以聚焦于算法本身的设计,不用关心下面资源如何提供的。开始的时候机器比较少,GPU 资源有限,大家使用方式基本是独占模式,直接面对存储和 GPU 资源。后来随着业务量增大,机器资源增多,平台的灵活性和扩展性越发显得重要。AVA 平台重点从对资源的包装到对资源的灵活调度转变。算法人员已经解除对资源的直接依赖,一个简单的命令或 GUI 操作就能启动训练。除了针对算法人员,目前这套系统也开始提供给外部用户使用,首先会给高校学生提供一个免费尝试深度训练的平台,后面将会具体介绍。
七牛云 AVA 平台主要有哪些部分组成?
第一个部分是数据集管理。这里讲的数据集管理包含几个部分。第一是如何管理 P 级别的云上云下数据,并能及时有效地提供给深度训练。第二是对数据进行加工处理,比如图片裁剪,把数据打包成不同深度训练框架所需的格式,自动挂载入深度训练平台进行训练。还有一种是如何把训练产生的结果自动回传。
第二就是标注。机器其实并不是一上来就能识别图片,很多时候需要人工辅助它,即要人先教会它怎么做。在信息大爆炸的时代,每天进来、出去可能 60% 以上都是图像、视频,这不是现有模型仓库里能准确识别出来的。AVA 平台提供一套打标机制(LabelX),让非专业或专业人士,通过标注手段,告诉平台这些图片到底是哪种类型,然后输入到训练算法进行模型迭代、更新,最后输出标准模型。基于产生的模型,我们就可以通过推理来判断新输入的图片是属于什么分类了,比如黄色,暴恐的等。目前七牛云对黄图识别的准确率已经达到 96% 以上。
同时,深度训练是平台比较重头的一块,包括对 GPU 资源的管理、存储资源的管理、训练管理, Quota 管理、以及跟深度训练相关的联合调度。现在七牛云有比较好的调度系统,比如 Kubernetes,但当真正使用的时候,发现 Kubernetes 能做的非常有限,调度管理粒度比较粗,只能调度到容器的级别。做到容器级别,可部分解决资源共享问题,比如 100 台 GPU,可以全部用起来。但如果有成千上万的并发训练任务,Kubernetes 的管理就有点捉襟见肘了,比如不同机器的 GPU 怎么联合调度、通信怎么管、资源怎么分配更合理等。七牛云现在要做的一件事,就是在 Kubernetes 调度之上,细化对 GPU、CPU 的管理,引入 RDMA 的技术,把资源管理、通信和调度做深,做细,达到更好的资源共享和使用。
最后一个部分,是评估推理。前期的训练做了大量准备工作,准备好了评估模型。推理评估要做的就比较简单,是把新的少量图片加上模型再训练一次,在毫秒级别能够得出结果。这一部分大都与业务结合比较紧密。
AVA 平台的技术架构是怎样的?
下图显示的是 AVA 平台的技术架构,主要分为三层。最下面一层属于硬件和资源管理层,我们现在基本不会买单台 GPU 做训练,一般我们都是做一个集群,这一块交给 Kubernetes 就可以了。最上面一层是业务系统,包括模型、推理、标注和各个不同的训练系统,七牛云 AI 实验室业务大部分业务都在这层。中间这层是 AVA 平台重点要发力的地方,也是我们现在重点在做的。

这层有三个部分:
第一部分是存储系统。这一部分的核心是如何把大量的数据管起来。较早我们的数据是直接搭在 CEPH 上使用,但数据量一旦达到几十 T 的规模,问题就开始显现了。举个例子,一个视频训练有几十 T 容量,包含十多亿张文件,存在 CEPH PVC 上,有一天突然发现数据读不了了,找了半天才发现是文件系统 inode 用完了。另外一个例子是,当 PVC 空间满了之后,新的数据进不来,老的数据不知道哪些该删,很被动。七牛云现在的一个策略,就是不再基于 CEPH 做训练,而是基于云做训练,CEPH 可以做中间缓存。目前中等规模的训练已经完全跑通,对于 IO 吞吐要求不是特别高的训练,和在 CEPH 上训练没有显著差别。目前 AVA 是通过 Alluxio 把本地训练和云上的数据对接起来。
第二是数据管理。所有数据都来源于互联网,开始都是存在对象存储中。AVA 刚做的时候,必须把数据拉到本地来才能训练。标准用法是,用户提供一个 json 文件,里面每行是七牛对象存储的 URL,AVA 会把 json 中每个文件都下载,放到一个 PVC 中并挂载到 Kubernetes 的 Pod 中进行训练。在存放到 PVC 之前,还会调用七牛的图像处理系统 Dora 对数据进行一些必要的操作如旋转,裁剪等。在现实使用中,大家会不停地调整数据内容并进行迭代训练,每次调整都重新把数据拉取一遍将是很繁琐的事情。现在我们的做法,一个是直接在云上训练,这样对数据的改动直接反馈到云端,另外一个是引入结构化存储,把数据和元数据信息存放到 Mongo 中,并通过打快照的方式,方便灵活的选择不同版本数据进行训练。
第三是调度管理系统。在七牛内部,现有比较成熟的框架比如 Caffe、MXNet、Pytorch、TensorFlow 等都在使用。最初是直接使用,后来迁移到七牛容器云,由 Kubernetes 提供调度,这样的调度还是比较简单的。比如, Kubernetes 现在的调度策略是,选中了 GPU 机器后,对 GPU 卡是随机选择。但是,一台机器上的两张 GPU 卡,处于不同拓扑连接方式,性能相差非常大。比如 QPI 连接带宽可能是 3GB,而 P2P 模式可能达到 12GB。AVA 通过检查 GPU 的 Affinity 模式,改写 Kubernetes 的 scheduler,避免选择处于不同 CPU 通道上的 GPU 卡。还有,现有的调度策略是让所有 GPU 机器卡使用比较均衡,但如果一个训练需要使用 8 张卡,系统中卡总数满足,可能没有一台机器可以提供完整的 8 张卡,AVA 通过定制策略,提供特殊的 scheduler,可以选择优先把 Pod 调度到部分分配的 GPU 机器上。对于分布式训练,七牛云调研过 Tensorflow、MXNet 等,最终选择 MXNet ps-lite 作为基础。MXNet 可以做分布式训练,但只能把任务调到机器里,调过去 GPU 怎么共享、使用,依然有很多东西可以优化。后续七牛云会基于 MXNet 的 PS-LITE 框架,把分布式调度往深里做,满足深度训练的需要。七牛云也正在引进 RDMA 机制,通过 RDMA 机制把 GPU 跟 GPU 之间联系打通,提升运行的性能。
对海量数据,七牛云怎么管?
之前数据管理的现状是:大部分的数据会存放在对象存储中,做训练的时候,会把数据拉到本地来。所谓本地,一般指本地的一个集群或本地一台机器,一般玩法,都是搭一个本地 CEPH 集群,通过 Kubernetes 调度,把 PVC 挂上去,然后训练数据从对象存储导到这里,可以在里面跑训练,跑一两个月或是一两天都可以。这样做的问题是用户数据不能共享,大家如果用过 CEPH 就知道,CEPH RBD 在 Kubernetes 中不能共享读写,CEPH FS 可以,但性能有点差距。还有,CEPH 提供的存储空间对于深度训练的数据量来说是杯水车薪。
去年七牛云搭了一个 100T 的集群,在真正用的时候感觉还是比较吃力,会碰到各种问题。一个训练,就可能有几十 T,把 CEPH 会一下子撑爆。这只是七牛内部一个正常的训练,算上对外开放的用户,还有内部上百号人同时使用,这个集群明显不能满足要求。
视频数据一下占几十 T,其他人没法玩了,这是比较头痛的一个问题。运维空间不够,可以加盘,加了几次以后就没法加了,或者盘位没了,然后再加机器,形成恶性循环。几十T的数据可能前面半个月用了一半数据就不用了,这个时候其实放在云上对象存储里就可以了。但刚开始没有这个机制,大部分的数据都躺着“睡觉”,而其他人又没有空间可用
对 GPU 也是类似,如果一个集群中的 GPU 不能充分利用,到最后会发现运维就是不停加盘、加机器,用户不停倒数据。这过程还会影响带宽,陷入恶性循环。怎么破这个问题?这是七牛云 AVA 要解决的问题,AVA 首先要解决痛点问题,然后才解决好用的问题。
存储问题怎么解决?
七牛云引入了一个 Alluxio 的特性。对七牛云来讲不只是单纯把一个开源系统引进,七牛云还会做优化、定制化,后期也会开源出去。Alluxio 这个系统现在相对比较成熟了,支持的厂家也很多,微软、百度、京东都用了这个系统,这个系统还算成熟。将来大家的数据可以直接放到七牛云存储上,直接利用 AVA 平台做训练,当然其中也会有些优化、定制。
为什么选 Alluxio?它有以下几个特性:
第一,支持多对象存储,海量空间。对七牛云来讲,CEPH 按百 T 级别,运维就很难做了。但对对象存储来讲,上 P 都不是问题,可能稍微慢一点,但数据放在这里,总归可以做训练,虽然有时候会慢,但通过其他的手段解决,至少先把空间问题解决了。
第二,统一命名空间。通过 Alluxio 做,就是一个大系统,做训练的时候,数据放到任何地方照样可以把数据拉过来,导入七牛云的深度训练平台,训练完以后把结果再导回原来的地方。
第三,内存分布式文件系统。比如一百台机器,每个机器贡献几百 G 内存形成几个 T 的内存系统,可以把数据放在里面,后续所有训练都是从内存读取,不会从云上读取,这是非常好的一个好处。在实际训练中,七牛云经常用到这个内存文件系统的特性。
第四,Multiple tier 缓存系统。内存可能是几个 T 的级别,现在七牛云本身训练数据已经到了 P 级别,加上后续平台开放出去,可能要到 E 级别,T 级别的内存系统对 E 级别的云上数据肯定不可用,这里就可以做一个多层的缓存系统,内存放不下了可以放在本地的硬盘。这一块可以不落 CEPH 空间,因为 CEPH 空间可能还要再走一次网络,速度会受影响,七牛云可以直接落到本地缓存系统。
Alluxio 在七牛的应用
首先为了考虑稳定性,七牛云会搭两套集群。
一个是只读 Alluxio 集群,会分配大量的 RAM,还有基于 SSD 裸盘作二级缓存,大部分的云上训练数据,可以落到这里。平时不繁忙的时候,数据可以完全落在 RAM 空间里。另外一个是 Alluxio 写集群,可以把训练过程产生的模型、log、qw、h 新文件等写入它,并通过同步或异步方式传回云上。写集群对接的不是 SSD 裸盘,而是 CEPH 集群。为什么考虑 CEPH?因为可以保证机器故障的时候,数据不会丢。写集群分配的 RAM 容量较少,数据写入的时候直接落入 CEPH,再次访问的时候才提升到 RAM 中。大部分的加速会在 Alluxio 读缓存集群, Alluxio 写集群也有加速功能,但不是主要的。
再上面对接的是 FUSE Adapter。这是基于 Kubernetes 的 Flex Volume 做的,可以把云上数据通过 Alluxio 直接导到训练平台。采用 Adapter 是为了安全原因,再通过 FUSE 就可以把数据挂进来。比如每个用户在七牛云 AVA 平台训练的时候,把 bucket 直接挂进来就行了,之后七牛云会自动把数据缓存到本地的系统,后续所有读写训练都走本地系统。从使用者角度来看,相当于在本地系统里做训练。通过这种方式,很大程度上简化了用户的使用。 AVA 把外面的这些东西都掩盖了,用户做训练的时候,根本看不到自己的 bucket,只看到自己的目录,当做本地目录直接读写就行了。
数据读写流程约为:
训练开始的时候,可以对数据预热,读取到本地 Alluxio 集群缓存起来,大部分框架都有这样的预取功能。或者不做预热,这样训练速度可能受损,但训练完全没有问题。RAM 充满以后,会把数据下沉到下一层的 SSD 盘。通过 FUSE 系统,训练所在的 POD 可以直接读取 Alluxio 的数据,就像读取本地文件系统文件一样。读取的其实不是云上的内容,内容已经存在集群内部了。这个集群容量完全可以替代原来的 CEPH 集群,另外的好处是数据不用的时候可以自动剔掉,大部分在使用的数据,在这个集群里都可以找得到,相当于把加速性能发挥到了极致。
而对写也是一样,但写七牛云有个不一样的地方。为了保证数据安全,写的话可以直接穿过 RAM 写入 CEPH,最终 RAM 或 CEPH 空间到达高水位了,可以自动把写入数据推到云上。训练完以后,异步的把一些干净数据淘汰,脏数据送回云上。
七牛云通过这个流程,把海量数据管理起来。用了这套系统后,大家就不需要频繁倒数据了,因为系统就可以自动把冷数据踢掉,也不会存在空间不够的问题了。以前用 CEPH 的时候盘很快会满,很多工程师不知道哪些数据该丢哪些该留,现在不需要考虑这些问题了。AVA 会自动把冷数据踢掉,自动把脏数据上传云。
计算资源管理
七牛云刚开始对 GPU 的使用还是比较原始的。比如通过 Kubernetes 启动 Pod 绑定 GPU,绑定以后跑训练,绑定以后,GPU 不能共享,而且 Pod 基本是停留在那,不释放。正确的使用方式应该是做一个 GPU 的池子,训练开始的时候分配、绑定 GPU,结束后马上归还,这是可以做到的。现在七牛云对计算资源的使用,也是遵循这个模式。七牛云采用了 workspace 和训练两种方式来管理使用计算资源。 Workspace 和训练共享用户的存储。用户通过workspace来编辑代码,准备数据并做简单的编译、调试。一切准备就绪后,从 AVA 平台启动训练实例,绑定 GPU,训练结束后,归还 GPU 到池子里,后面的训练可循环使用。

现在所有的新用户不能直接看到 GPU,具体训练的时候他不知道用的是哪几个 GPU,放在哪里。较早的时候大家占住几个 GPU 一直使用,不释放,别人没法共享。现在七牛云把它做成一个池子, GPU 就完全可以流转起来。以后的目标,就是用少数的 GPU 可以做大量的训练。目前,七牛云正在加一些新的特性,比如加 quota,分组机制,这样可以避免少数人无限制地霸占 GPU。
如何解决使用 GPU 存在问题?
如何解决使用 GPU 存在问题,典型的问题是:GPU 的调度问题。
Kubernetes 的调度策略是比较简单的,先通过 predicate 检查,再通过 priority 检查,然后由 Kubelet 具体分配绑定资源。假如有两台 GPU 机器,每台 8 张卡,第一台已经分配出去 2 张卡了,再次申请 2 张卡的时候,Kubernetes 很可能会调度到第二台机器上,这样每台机器都使用了 2 张卡。如果这时有个训练要求使用同一台机器上的 8 张卡训练,调度将失败。这个时候需要把调度改掉,第二次分配在选择第一台机器的 GPU,第二台机器的 8 张卡可以完整留下来。通过不同策略就可以满足不同的需求。还有,假设是单台机器上选择两张 GPU 训练,如果选 GPU1 和 GPU3,它们属于不同 CPU,通过 QPI 链接,它们之间带宽可能只有是 3 个 GB 每秒。如果选择 GPU0 和 GPU1,它们之间属于同一个 CPU,那么带宽可能达到 12G 每秒。调度的时候尽量要选择 GPU0 和 GPU1 在一起。
实测中,七牛云也发现,比如内存和 CPU 有一定限制的情况下,通过不同的 GPU 分配方式跑的训练时间差异非常大,最多性能差距达到1倍以上。将来一旦扩大到整个集群,差别会更大。所以 GPU 的调度模式对训练影响会非常大。
AVA 平台的展望
原来七牛云内部从业务角度出发,也做了一个分布式的训练系统 ESPP,用于图像和视频训练,其中也用到了 Kubernetes 和一些训练框架,但是针对于特定业务系统的。现在七牛云准备把原来的业务系统都收编到 AVA 平台。 RDMA 这一块也是要重点考虑的,正在跟厂家做一些沟通交流,马上就要布上去,加上分布式调度系统,以后训练会比现在快很多。
虽然说现在 AVA 有了分布式的调度机制和 RDMA 机制,但从算法模型的生产角度讲,还处在一个手工阶段,大家还是通过手工方式不停的调整参数,然后不停的跑训练,以期调试出一个满意的模型。目前 Google 已经通过 AutoML 的方式自动能产生出很好的模型,七牛云还有很多路要走。七牛云正在和算法团队一起研究,如果让模型训练变得更高效,更自动化,更智能化。
总结
这套 AVA 系统,不仅七牛云内部使用,现在已经推广给高校学生免费使用。第一步已经准备了几十张 GPU 卡和常用的训练框架,登陆到平台后就可直接使用。高校学生遵循下面几个步骤就可以非常方便的使用 AVA 平台: