|
北京2015年12月22日电 /美通社/ -- 企业级基础云服务商青云QingCloud(www.qingcloud.com )日前宣布,基于Hadoop的大数据集群服务现已正式推出。该服务包括三大核心组件,即HDFS分布式文件系统、YARN任务调度和集群资源管理系统,以及MapReduce并行计算系统。通过QingCloud Hadoop集群服务,用户能够在2-3分钟内创建一个Hadoop集群,并且可以进行横向和纵向的在线伸缩,极大地降低了Hadoop平台的技术门槛。

Hadoop是一个针对海量大数据进行存储和处理的分布式开源平台,在大数据领域的应用极为广泛。它使用简洁的MapReduce编程模型分布式处理跨集群的大型数据集,集群规模可以扩展到几千甚至上万。QingCloud Hadoop集群服务采用Master/Slave架构,由三种节点类型构成,即主节点(YARN Resource Manager和HDFS Name Node)、从节点(YARN Node Manager和HDFS Data Node),以及客户端节点(Hadoop Client Node)。用户在客户端节点发起MapReduce任务,通过与HDFS和YARN集群中各节点的交互存取文件、执行MapReduce任务,最终获取结果。

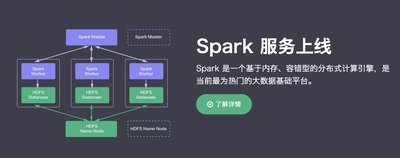
早在2015年8月,青云QingCloud就已推出基于Spark的大数据集群服务,此次Hadoop集群服务的上线是对QingCloud大数据基础平台的有力补充。Hadoop和Spark各有千秋,Hadoop适用于更大规模的离线数据处理,且对系统故障具备天然的抵抗力;Spark更适合做快速的实时数据分析。因此,用户可以根据应用场景的不同,选择灵活的大数据解决方案。
具体而言,青云QingCloud Hadoop集群服务具有以下特性:
青云QingCloud CTO甘泉(Reno Gan)表示,Hadoop集群服务的推出标志着QingCloud大数据基础平台的进一步完善,结合已经推出的Spark、ZooKeeper、消息队列(Kafka)、Redis、Memcached、MongoDB等服务,QingCloud的大数据平台服务已经能够越来越灵活地满足用户的各种需求,实现用户数据价值的较大化。